[추천시스템 논문 리뷰] MMGCN : Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video
Background
온라인 컨텐츠 플랫폼에서 추천 시스템(Recommender System)은 사용자 만족도를 끌어올리고 매출을 증대시키는 데에 중요한 역할을 한다. 추천의 품질을 높이기 위해, 컨텐츠의 Feature 데이터를 추천에 이용하는 연구(Multi-Model Recomendation)가 활발히 진행되고 있다.
Problem Statement
논문이 작성된 2019년 기준으로, 기존 멀티모달 추천 모델들은 Feature 데이터를 그대로 기존의 협업 필터링(Collaborative Filtering) 모델에 집어넣는 정도에 그쳤다는 것이다. 협업 필터링 모델에서는 주로 사용자가 어떤 상품을 좋아했는지(혹은 싫어했는지)를 가지고 모델링을 진행하는데, 이와 같은 상황에서 멀티모달 정보를 상품 데이터의 일부로 취급해 버리면 다음과 같은 논리를 펼치는 것과 같다.
- 민수는 타이타닉이라는 영화를 좋아한다.
- 타이타닉이라는 영화는 다음과 같은 Multi-Model Feature를 가진다.
- 배경음악(Acoustic Feature)
- 시놉시스(Textual Feature)
- 영상미(Visual Feature)
- 따라서 민수는,
- 타이타닉과 비슷한 Acoustic Feature를 가진 다른 영화도 좋아할 것이다.
- 타이타닉과 비슷한 Textual Feature를 가진 다른 영화도 좋아할 것이다.
- 타이타닉과 비슷한 Visual Feature를 가진 다른 영화도 좋아할 것이다.
하지만 이 논리에는 오류가 있다! 민수는 타이타닉의 줄거리와 음악은 높게 평가하지만, 영상미에는 불만이 있을 수도 있지 않은가? 즉, 본 논문에서는 사용자의 Feature 선호도를 각 Modality마다 따로따로 모델링해야 한다는 점을 지적하고 있다.
Proposed Solution
따라서 저자들은 Multi-Modal Feature데이터를 그대로 CF 프레임워크에 집어넣기보다는, 각 사용자가 상품의 Multi-Modal Feature 각각에 대해 어떤 선호도를 가지는지를 직접적으로 모델링하는 접근을 제시한다. 이러한 선호도 데이터를 표현할 수 있는 방법 중 하나는 최근 각광받는 그래프(Graph) 데이터 구조로, 본 논문에서는 그래프 데이터를 직접 다룰 수 있는 Graph Convolutional Network를 이용해 모델링을 시도한다.
Graph Convolution
2차원 평면(e.g. 이미지 픽셀 데이터)에서 인접한 8방향(3x3 필터 기준)의 정보를 Convolution Layer를 이용해 취합하듯이, 그래프에서도 인접한 노드의 정보를 취합할 수 있다. 차이점이라면 취합하는 정보의 수가 가변적이라는 것이다. 따라서 그래프에서 Convolution을 행할 때에는 우리가 아는 Convolution Layer의 일반화된 형태가 필요하다. 그래프 기반의 인공신경망(GNN)으로 뛰어난 성과를 거둔 첫 논문에서는 Graph Convolution 함수를 다음과 같이 정의했다.
\[\begin{align*} {\bf X}^{(h+1)}&={\bf D}^{-\frac{1}{2}}({\bf A+I}){\bf D}^{-\frac{1}{2}}{\bf X}^{(h)}\hat{\bf \Theta}\\ {\bf x}^{(h+1)} &= {\bf \Theta}^{\text T}\sum_{j\in\mathcal{N}(i)\cup\{i\}}\frac{e_{j,i}}{\sqrt{d_j d_i}}{\bf x}_j \end{align*}\]- 위 수식은 Graph Convolution의 과정을 Graph-Level에서 표현한 것이고, 아래 수식은 Node-Level에서 표현한 것이다.
- $\Theta$는 Graph Convolution Layer가 가지는 학습 가능한 파라미터이다.
- $\bf A$는 특정 노드가 어떤 노드와 이웃해 있는지를 나타내는 Adjacency Matrix이다. 단, 이 행렬은 자기 자신과의 연결을 표시하지 않고 있기 때문에 단위행렬 $\bf I$를 더해서 스스로의 정보 또한 취합한다.
- ${\bf D}$는 노드의 이웃 수를 나타내는 Degree Matrix로 대각성분 이외의 성분은 0이며, ${d}i={\bf D}{ii}$이다.
- $\mathcal{N}(i)$는 이웃 노드의 집합이고, 따라서 $j\in\mathcal{N}(i)\cup{i}$는 노드 $i$와 그 이웃 노드들의 집합을 뜻한다. $e_{j,i}$는 $j$에서 $i$로의 edge weight를 나타내며, 기본적으로 1이다.
💡 정리
Graph Convolution 후의 Node Representation은, 이전 단계의 이웃 노드들의 Representation들의 Normalized Weighted Sum의 Linear Projection으로 구성되며, 이후 Activation Function을 통과할 수 있다.
Message Passing
방금 소개한 수식은 노드 ${\bf x}^{(h)}$의 representation을 받아서 다음 노드 ${\bf x}^{(h+1)}$의 표현을 계산하는 방법이다. 하지만 이것은 예시일 뿐이고 얼마든지 새로운 방식으로 다음 노드의 표현을 계산할 수 있다. 실제로 GCN이 각광받기 시작한 이후에는 각 Task에 알맞게 개량된 각종 창의적인 Message Passing Scheme이 등장해 성능을 다투고 있다. 본 논문에서도 독자적인 Message Passing Scheme이 등장하는데, 먼저 그 Scheme을 구성하는 두 가지 요소를 알아보자.
Aggregation Layer
주변 노드의 표현을 취합하는 단계이다. 두 가지 방식이 있다.
Mean Aggregation. 이웃한 노드의 표현들을 Linear Projection 시킨 뒤에 평균을 내는 것이다. 이후 활성화함수를 통과시킨다.
\[{\bf h}_m = \text{LeakyReLU}(\frac{1}{|\mathcal{N}_u|}\sum_{j\in\mathcal{N}_u}{\bf W}_{1, m}{\bf j}_m)\]위 수식에서 $\mathcal{N}_u$는 $u$의 이웃 노드, $|\mathcal{N}_u|$는 이웃 노드의 수, ${\bf W}_{1,m}$은 Convolution Layer의 파라미터가 되는 weight matrix를 뜻한다. 1은 다른 weight matrix와의 구분을 위해 붙인 것이고, $m$은 시각/청각/텍스트 modality 중 하나를 표기하기 위한 것이다.
Max Aggregation. 이웃한 노드의 표현들을 Linear Projection 시켜 얻은 벡터들로부터, 각 차원에서 가장 큰 값만을 취합해 새로운 벡터를 완성시킨다. 이후 활성화함수를 통과시킨다.
\[{\bf h}_m = \text{LeakyReLU}(\max_{j\in\mathcal{N}_u}{\bf W}_{1, m}{\bf j}_m)\]
Combination Layer
Aggregation Layer를 통해 얻어지는 ${\bf h}_m$은 이전 단계에서 이웃해 있던 노드들의 표현을 취합한 것으로 볼 수 있다. Combination Layer에서는 여기에 각종 추가적인 정보를 주입한다. 구체적으로는 자기 자신의 벡터표현에 해당하는 ${\bf u}_m$과, one-hot 인코딩된 ID 벡터 ${\bf u}_{id}$ 가 추가된다.
${\bf h}_m$은 자기 자신의 벡터표현과는 무관하기 때문에 $u$에 해당하는 벡터표현 ${\bf u}_m$의 개입이 필요하다. ${\bf u}_{id}$는 딥러닝을 이용한 추천 시스템에서 줄곧 사용되는 컨셉으로, 꾸준히 좋은 성능을 자랑하기에 MMGCN에서도 등장한 것으로 보인다(개인적으로 꼭 필요한 이유는 잘 모르겠다).
Combination Layer에도 두 가지 종류가 있다.
Concatenation Combination.
\[\begin{align*} \hat{\bf u}_m&=\text{LeakyReLU}\big({\bf W}_{2,m}{\bf u}_m\big)+{\bf u}_{id}\\ {\bf u}_m^{(1)}&=\text{LeakyReLU}\big({\bf W}_{3,m}({\bf h}_m||{\bf \hat{u}}_m)\big) \end{align*}\]Element-wise Combination.
\[\begin{align*} \hat{\bf u}_m&=\text{LeakyReLU}\big({\bf W}_{2,m}{\bf u}_m\big)+{\bf u}_{id}\\ {\bf u}_m^{(1)}&=\text{LeakyReLU}\big({\bf W}_{3,m}{\bf h}_m+{\bf \hat{u}}_m\big) \end{align*}\]
수식을 살펴보면 자기표현을 나타내는 두 벡터(Embedding 에 해당하는 ${\bf u}_m$과 One-hot encoded Identity Vector ${\bf u}_{id}$)를 합치는 과정은 동일하다. 자기표현을 Linear Projection 시킨 뒤 활성화함수를 통과시키고, 거기에 ID 벡터를 더해주는 방식이다. 이후 그 결과물을 어떻게 ${\bf h}_m$과 합칠 것인지가 문제인데, $\hat{\bf u}_m$을 이어지는 Linear Projection의 영향을 받게 할 것인지 말 것인지가 두 접근의 차이라고 할 수 있겠다.
Input Data
위 단락에서는 노드 $u$와 그 표현 ${\bf u}_m^{(h)}$가 주어졌을 때, 정의된 Graph Convolution 규칙에 따라서 다음 표현 ${\bf u}_m^{(h+1)}$을 얻어내는 과정을 설명했다. 이제 구체적인 모델의 구조를 알아보자.
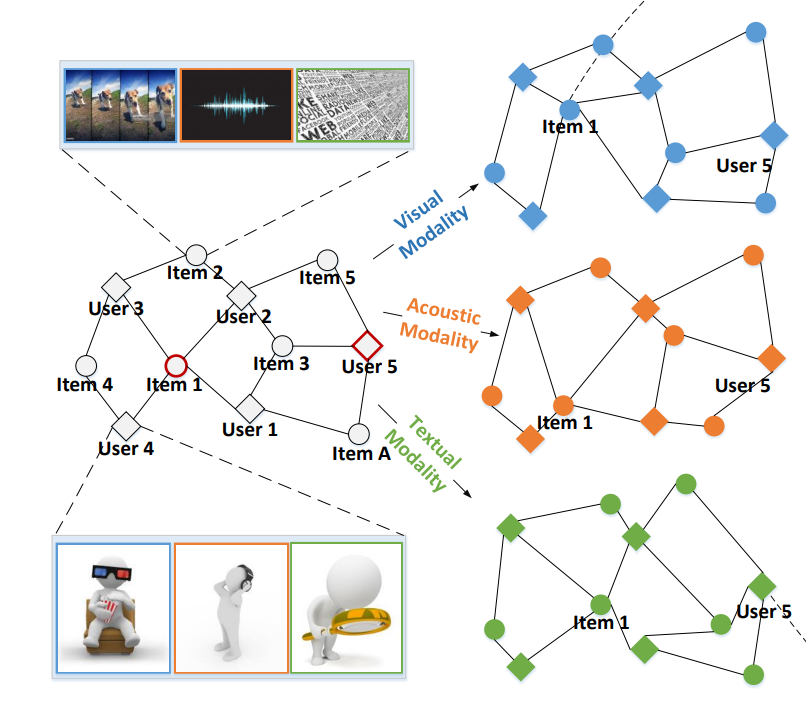
가장 좌측의 그래프는 User-Item Graph로, 사용자 노드와 상품 노드가 공존하는 Undirected Heterogeneous Bipartite 그래프이다. 사용자와 상품 사이에 Edge가 존재한다면 해당 사용자가 그 상품과 상호작용했음을 나타낸다. 또한, 각 노드는 벡터 표현을 가진다. 우리는 이 벡터 표현을 학습하는 Representation Learning에 관심이 있다.
User-Item Graph로부터 Visual/Acoustic/Textual 피쳐를 가지는 3개의 그래프(파란색, 주황색, 초록색 그래프)를 만들어낼 수 있다. 이 그래프들의 노드와 엣지는 User-Item Graph와 동일하지만, 노드들이 가지는 벡터 표현은 각자 독립적이다.
- User Node가 가진 벡터 표현은 학습 가능한 파라미터이다.
- Item Node가 가진 벡터 표현은 고정된 값이다.
- 뭐라고? 일반적으로 추천 시스템에서는 User Embedding과 Item Embedding을 학습하게 된다. 하지만 우리에게는 Multi-Modal Feature 데이터가 있으므로, Feature Data를 Vector Space에 잘 Mapping해 둔 Foundation Model들의 힘을 빌릴 수 있는 것이다.
- Visual Feature의 경우 Pre-trained ResNet50 모델을 활용해 Embedding을 얻는다.
- Textual Feature의 경우 Sentence2vec 기법을 이용하여 Embedding을 얻는다.
- Acoustic Feature의 경우 VGGish를 이용하여 Embedding을 얻는다.
Stacking More Layers
입력 데이터는 준비되었으니, 위에서 정의된 Message Passing Scheme을 따라 Graph Convolution을 진행할 수 있다. $(h+1)$번째 layer에서,
- User 노드의 표현 벡터는 $(h)$번째 layer의 Item 노드들의 표현을 취합하여 만들어진다.
- Item 노드의 표현 벡터는 $(h)$번째 layer의 User 노드들의 표현을 취합하여 만들어진다.
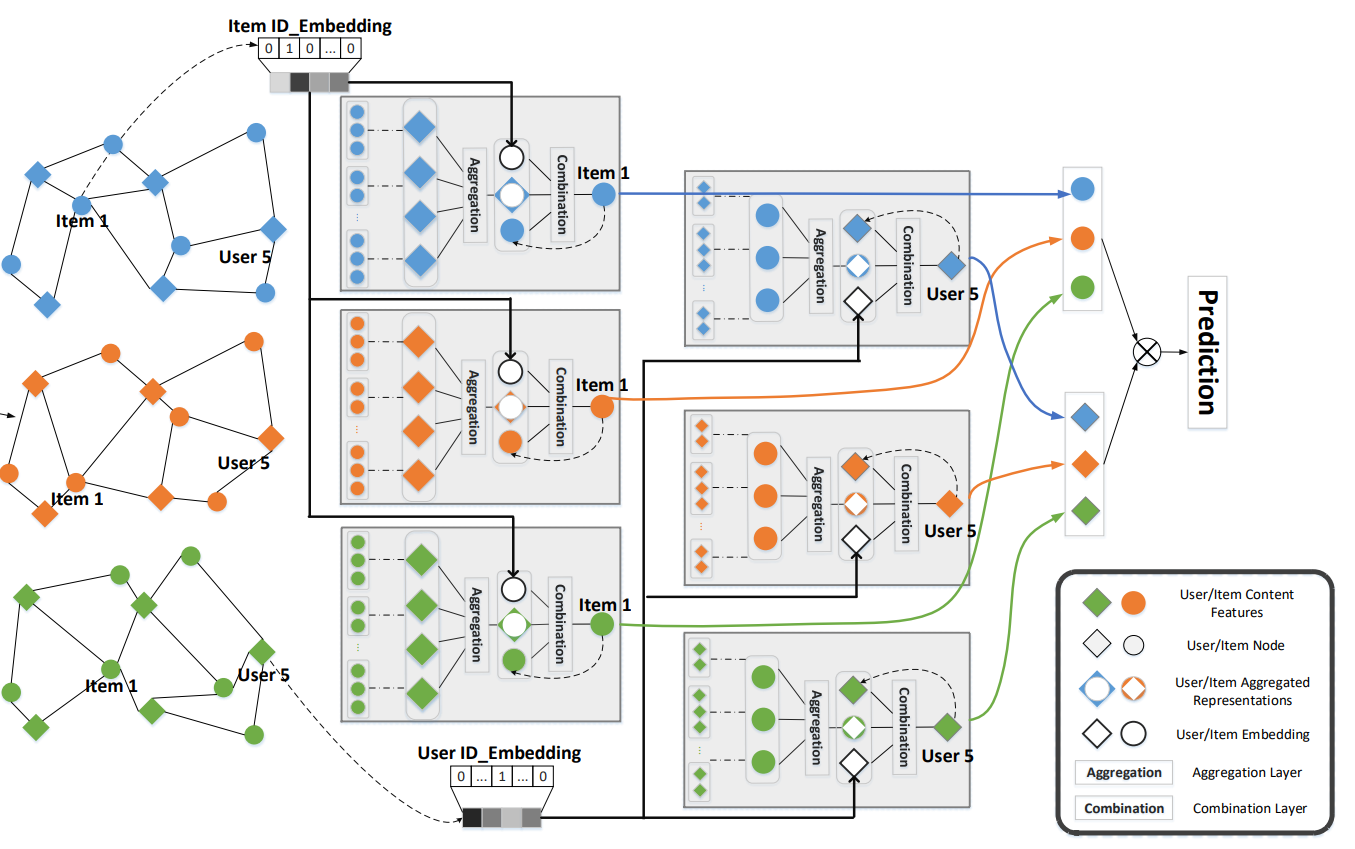
따라서 각 layer에서는 User Node들과 Item Node들에 대해 Aggregation과 Combination을 각각 적용하여 새로운 User Representation과 Item Representation을 출력하게 된다. 이것을 그대로 다음 층에 입력하는 것으로 layer를 계속 쌓아나갈 수 있다. Layer를 $l$번 쌓는 것으로 $l$-hop neighbor들의 표현까지 취합할 수 있다(본 논문의 실험에서는 2개의 layer를 사용했을 때 최적의 실험 결과를 관측하였다).
Loss Function
$l$개의 레이어를 통과하면 각 Modality에 해당하는 Graph는 모든 User/Item의 벡터 표현을 보유하게 된다. 이것을 모든 Modality에 대해 합산한 것이 최종 User/Item의 벡터 표현이 된다.
\[{\bf u}^*=\sum_{m\in\mathcal{M}}{\bf u}^{(L)}_m \space\space\space\space \text{and} \space\space\space\space {\bf i}^*=\sum_{m\in\mathcal{M}}{\bf i}^{(L)}_m\]위 수식에서 $\mathcal{M}={v, a, t}$이며, Visual/Acoustic/Textual 모달리티를 포함하는 집합을 의미한다. User/Item Representation을 계산했으면 추천시스템에서 꾸준히 사용되는 BPR Loss를 이용해 모델을 최적화한다.
\[\mathcal{L}=\sum_{(u,i,i')\in\mathcal{R}}-\ln\sigma({\bf u^{*\text{T}}}{\bf i}^*-{\bf u^{*\text{T}}}{\bf i}'^*) + \lambda||\Theta||^2_2\]BPR Loss를 간단히 설명하자면 다음과 같다.
- 어떤 사용자가 특정 상품을 선호하는 정도를 User Vector와 Item Vector의 내적(Dot Product)으로 모델링한다. 이것은 매우 고전적인 추천 기법인 Matrix Factorization 부터 사용되던 방식이다.
- 사용자$(u)$가 상호작용한 상품$(i)$을 선호하는 정도를 $\bf u^{*\text{T}}{\bf i}^*$로 표현된다. 또한 상호작용하지 않은 상품$(i')$을 선호하는 정도는 ${\bf u^{*\text{T}}}{\bf i}'^*$로 표현된다.
- 그렇다면 위 수식에서 ${\bf u^{*\text{T}}}{\bf i}^*-{\bf u^{*\text{T}}}{\bf i}'^*$를 최대화하는 것은, $\bf u^{*\text{T}}{\bf i}^*$를 최대화하면서 동시에 ${\bf u^{*\text{T}}}{\bf i}'^*$를 최소화하는 것을 의미한다.
- 또한 수식에서 $\sigma$기호는 Sigmoid 함수를 의미한다. 이 활성화 함수를 통과함으로써 치역이 $(0, 1)$로 한정되고, 확률로써 해석이 가능해진다. 수식에서는 Sigmoid 함수를 통과한 값의 부호를 바꾸고 자연로그를 씌움으로써, 최대화 문제를 Negative Log Likelihood를 최소화하는 문제로 전환하였다.
- 마지막으로 $||\Theta||^2_2$와 $\lambda$는 각각 L2 Regularization 항과 그 정도를 조절하는 Hyperparameter에 해당한다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!