[추천시스템 논문 리뷰] Monolith : Real Time Recommendation System with Collisionless Embedding Table
Background
2020년대부터는 SNS 시장에 숏폼 컨텐츠가 급부상하며, 짧고 강한 자극에 말초신경이 절여진 우리의 시간을 삭제하고 있다. 숏폼 콘텐츠의 주요 성공 요인 중에서 단연 돋보이는 것은 바로 헤어나올 수 없는 마성의 추천 알고리즘이다. 숏폼 컨텐츠의 원조이자 선두주자인 틱톡(TikTok)의 모회사 바이트댄스(ByteDance)에서는 어떤 방식으로 대규모 추천 엔진을 구축하였는지 살펴보자.
이하 소개할 내용은 바이트댄스에서 B2B로 제공하는 상품 추천 솔루션인 BytePlus Recommend에 실제로 사용되고 있는 아키텍쳐이다. 모델링적인 내용보다는 ML Engineering에 초점이 맞춰져 있으며, 연구에서 사용하는 환경과는 다른 현실의 환경에 적응하기 위해 어떤 조치를 취했는지의 내용이 담겨져 있다.
The Monolith Architecture
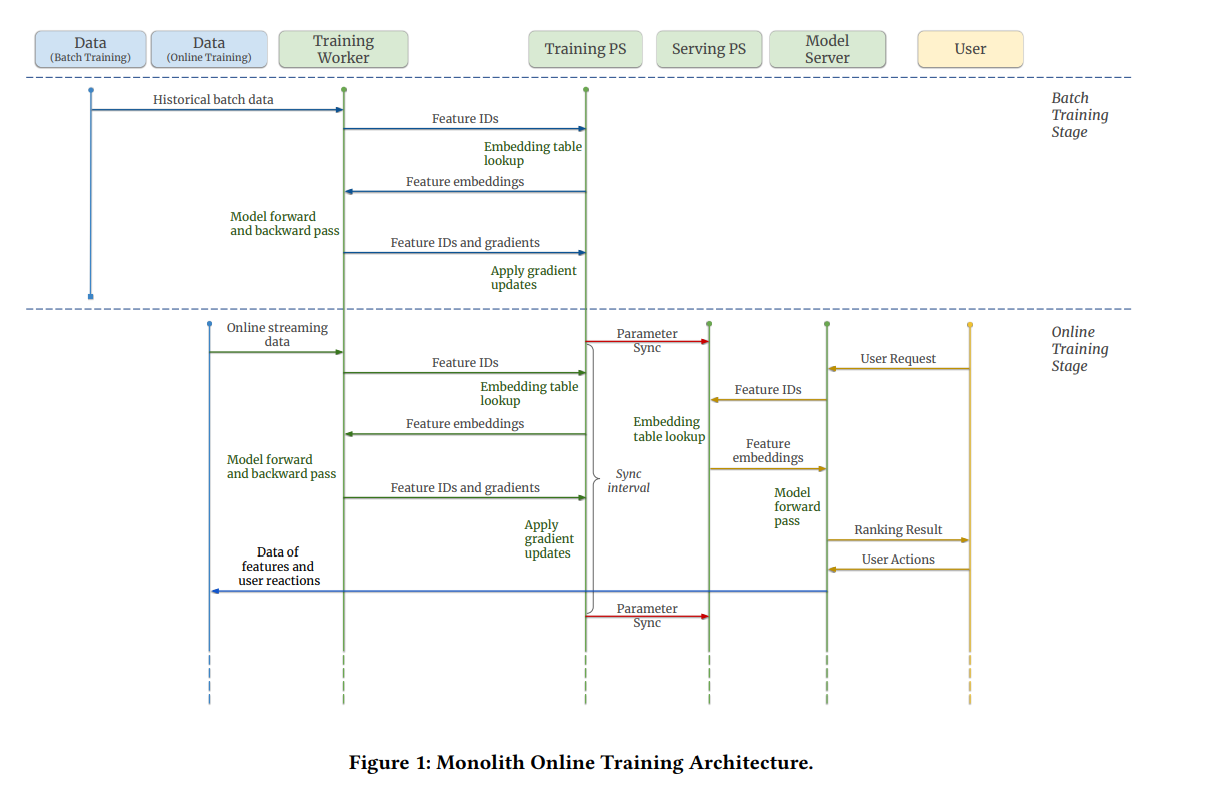
본 논문에서는 실시간 학습(Online Learning)에 특화된 대규모 추천 시스템 아키텍처를 제안한다. 모노리스(Monolith)라 명명된 이 아키텍처의 시퀀스 다이어그램을 살펴보면서 각 컴포넌트가 어떤 역할을 하는지 뜯어보겠다.
- 학습 파라미터 서버(Training Parameter Server).
- 대규모 머신러닝에서는 모델이 너무나 커서 컴퓨터 하나로는 학습할 수 없기 때문에 분산 컴퓨팅을 이용한다. 그렇기 때문에 비동기 학습(Asynchronous Training)을 진행하는데 이것을 위해서는 여러 대의 머신에서 모델 파라미터를 동시에 접근하고 업데이트할 수 있어야 한다.
- 이것을 가능하게 하는 것이 파라미터 서버이다. 분산 머신러닝 환경에서 하나의 머신은 워커 노드 혹은 파라미터 서버로써 기능하게 된다.
- 서빙 파라미터 서버(Serving Parameter Server)
- 최종적으로 사용자에게 추천을 제공할, 추론 서버의 파라미터를 담당한다.
- Training PS의 파라미터들은 매우 자주 변한다. 이는 분산 컴퓨팅 환경에서 매우 작은 단위로 파라미터 업데이트가 진행되기 때문이다. Serving PS에서는 굳이 모든 파라미터 업데이트를 모두 기록할 필요가 없으므로, 주기적으로(e.g. 1분마다, 5분마다, 1시간마다, 1일마다) Training PS의 파라미터를 Serving PS로 업데이트한다.
- 학습 워커(Training Worker)
- 일반적으로 여러 개의 머신으로 구성된다. 각 워커 노드에서는 Loss를 계산하고 Backprop을 통한 Gradient 계산 등이 이루어진다.
- 또한 이곳은 모델의 Forward Pass에 해당하는 작업을 수행하는 곳이다. 즉 이곳에서 User/Item ID를 입력받아서 Training PS에 User/Item Embedding을 요청하게 된다. Gradient를 계산한 뒤에는 그 값을 다시 Training PS에 전달하고, Training PS는 전달받은 Gradient값에 따라 파라미터를 업데이트한다.
- 모델 서버(Model Server)
- 학습 워커와 동일하게 User/Item ID를 입력받고, Serving PS에 Embedding을 요청한 뒤, 모델의 Forward Pass를 진행해서 추천을 제공한다.
Training with Monolith
Batch Training
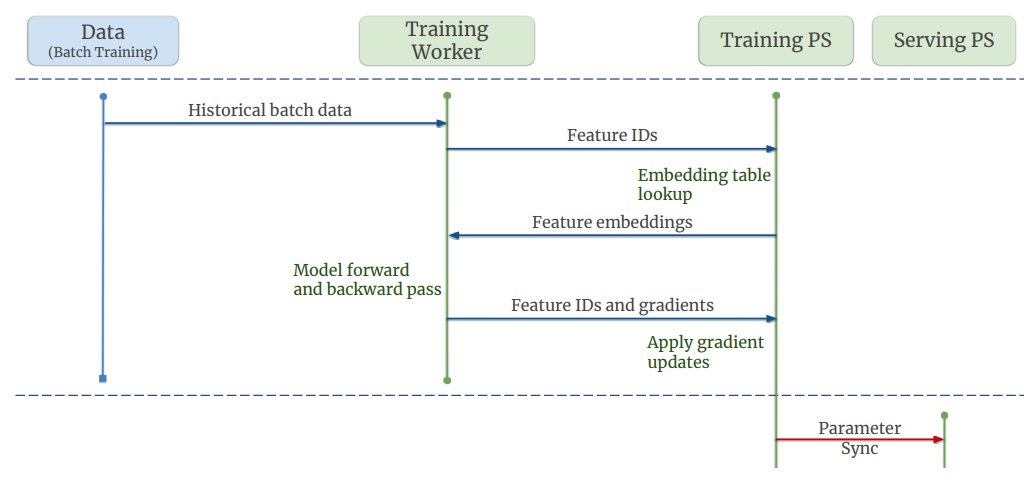
Monolith에서는 두 종류의 학습이 진행된다. Batch Training과 Online이 그것인데, Batch Training은 우리가 흔히 아는 머신러닝/딥러닝 과정을 떠올리면 될 것이다. 중요한 차이점이 하나 있는데,
“우리는 학습 시에 데이터셋을 한 번만 훑습니다.” “We only train our dataset for one pass.”
다시 말해서 딱 1 Epoch만 사용해서 모델을 훈련한다는 것이다. 이는 이어질 Online Training 단계에서의 학습을 무의미하게 만드는 오버피팅을 경계한 것으로 보인다. 데이터셋이 워낙 방대하기 때문일 수도 있겠다.
Batch Training을 위한 데이터는 하둡 파일시스템(Hadoop Distributed File System, HDFS)에서 읽어온다. 모든 과거 데이터를 이용해 모델을 훈련하고, Training PS에서 Serving PS로 파라미터를 Push하면 Batch Training이 종료된다.
Online Training
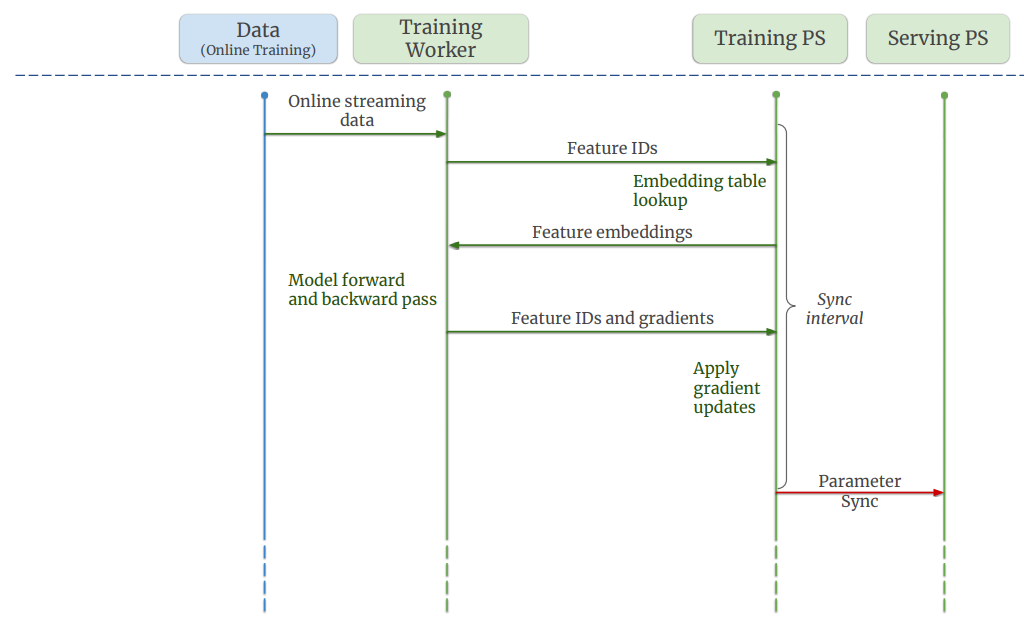
이후부터는 Online Training 모드로 전환된다. 이 단계에서는 과거 데이터를 사용하는 대신 실시간으로 사용자가 남기는 로그 스트림(Stream)의 데이터로 모델을 학습한다.
바이트댄스에서는 스트림을 관리하기 위해 오픈소스 툴 Kafka를 사용한다. Kafka Queue에 데이터를 순차적으로 집어넣어 두면, Consumer가 원할 때에 데이터를 수령할 수 있고, 입력 순서가 유지된다.
- Log Kafka. 사용자가 상품을 열람할 때 발생하는, User/Item ID 데이터가 담긴 스트림이다.
- Feature Kafka. User/Item ID에 해당하는 Feature Embedding 데이터가 담긴 스트림이다. User/Item ID가 주어지면, 그에 대한 Feature는 파라미터 서버로부터 공급받는다.
두 개의 Kafka Queue는 비동기적으로 값이 전달되기에, 각 요청마다 Interaction ID와 같은 형태로 Key값을 보존해야 정확한 데이터셋 구성이 가능하다. 두 Kafka Queue로부터 전달받은 값은 Online Joiner에 전달된다.
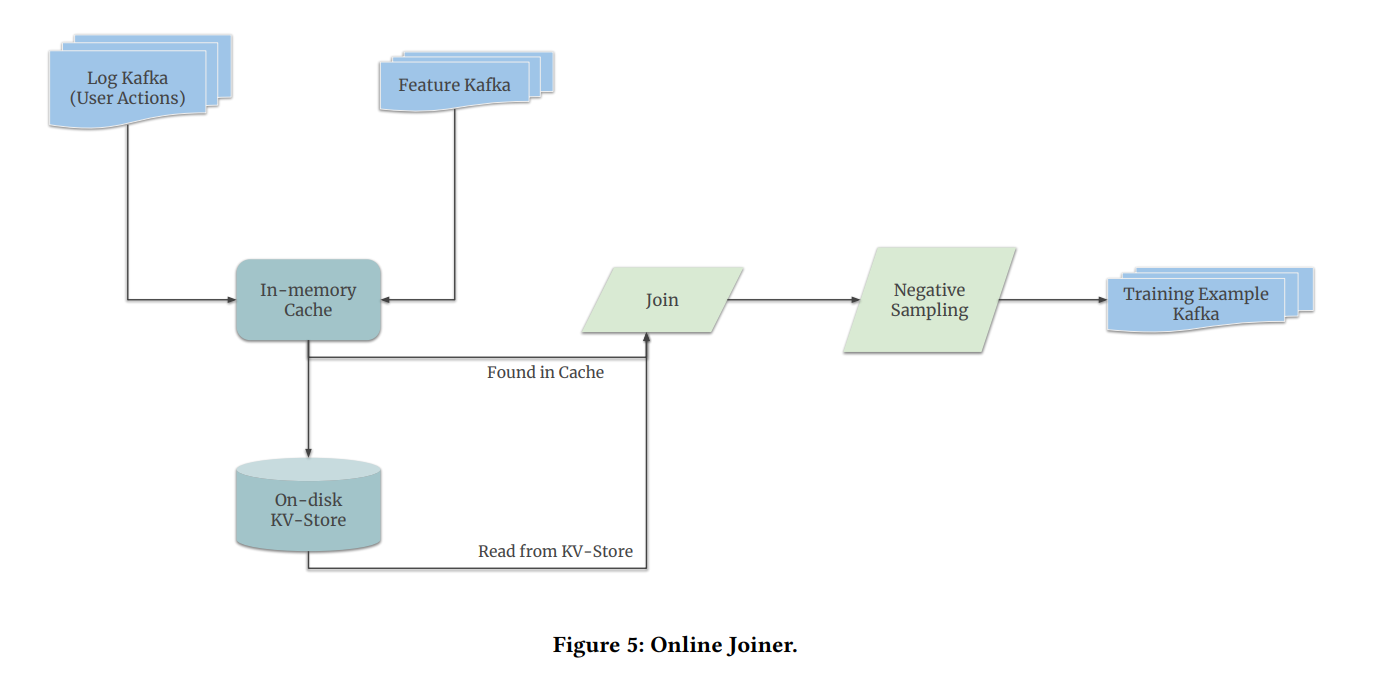 Online Joiner의 아키텍쳐 도면. 2개의 Kafka Queue로부터 데이터를 받아 아래와 같은 Training Example을 생성한다. 이 작업에는 캐싱이 활용된다.
Online Joiner의 아키텍쳐 도면. 2개의 Kafka Queue로부터 데이터를 받아 아래와 같은 Training Example을 생성한다. 이 작업에는 캐싱이 활용된다.
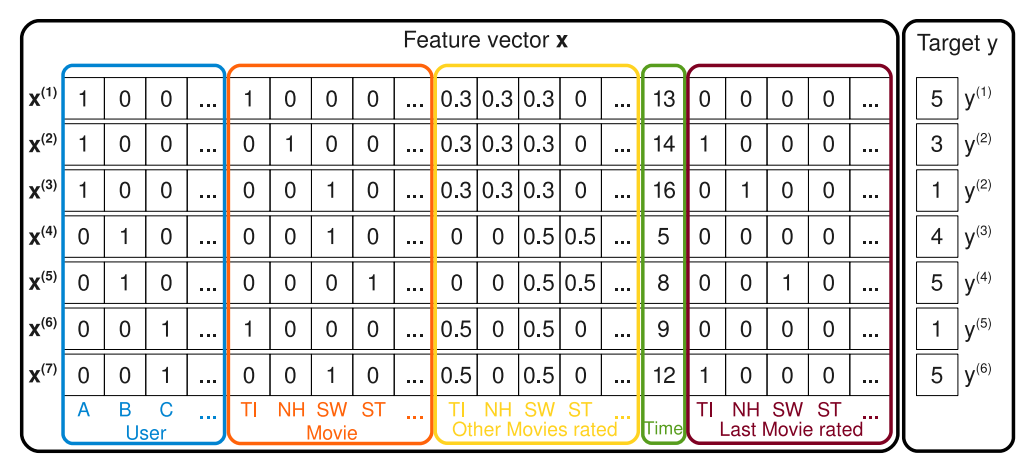 Online Joiner가 Feature Embedding들을 취합하여 생성하는 데이터포인트의 예시.
Online Joiner가 Feature Embedding들을 취합하여 생성하는 데이터포인트의 예시.
Online Joiner는 Feature Embedding을 입력받아서 최종적으로 데이터포인트 하나를 생성한다. 우리가 익히 알고 있는, Factorization Machine이나 Neural Collaborative Filtering 등의 모델에서 사용되는 형태의 입력 데이터가 한 줄 생성된다고 이해하면 좋을 것이다!
Caching. 또한 이렇게 Embedding을 취합하는 작업에는 캐싱(Caching)을 활용한다. 같은 작업을 반복하는 것은 비효율적이기에 미리 계산해둔 결과값을 보존하여 추후 동일한 입력이 들어왔을 때 결과만을 반환하는 것이다. 단, 모든 값을 메모리에 보존할 수는 없으므로 입력받은 지 오래된 데이터는 메모리에서 내리고 하드 디스크에 저장한다.
Negative Sampling. 결국 Online Joiner는 훈련에 사용되는 Tabular Data를 생성하게 된다. 이렇게 생성된 데이터셋에는 Positive Example뿐만 아니라, Negative Example도 있어야 모델을 훈련할 수 있다. 따라서 Positive Example을 생성한 직후 Negative Sampling이 이어지며, 이후 이것을 또 다른 3번째 Kafka Queue에 등록하는 것으로 Online Joiner의 임무가 종료된다.
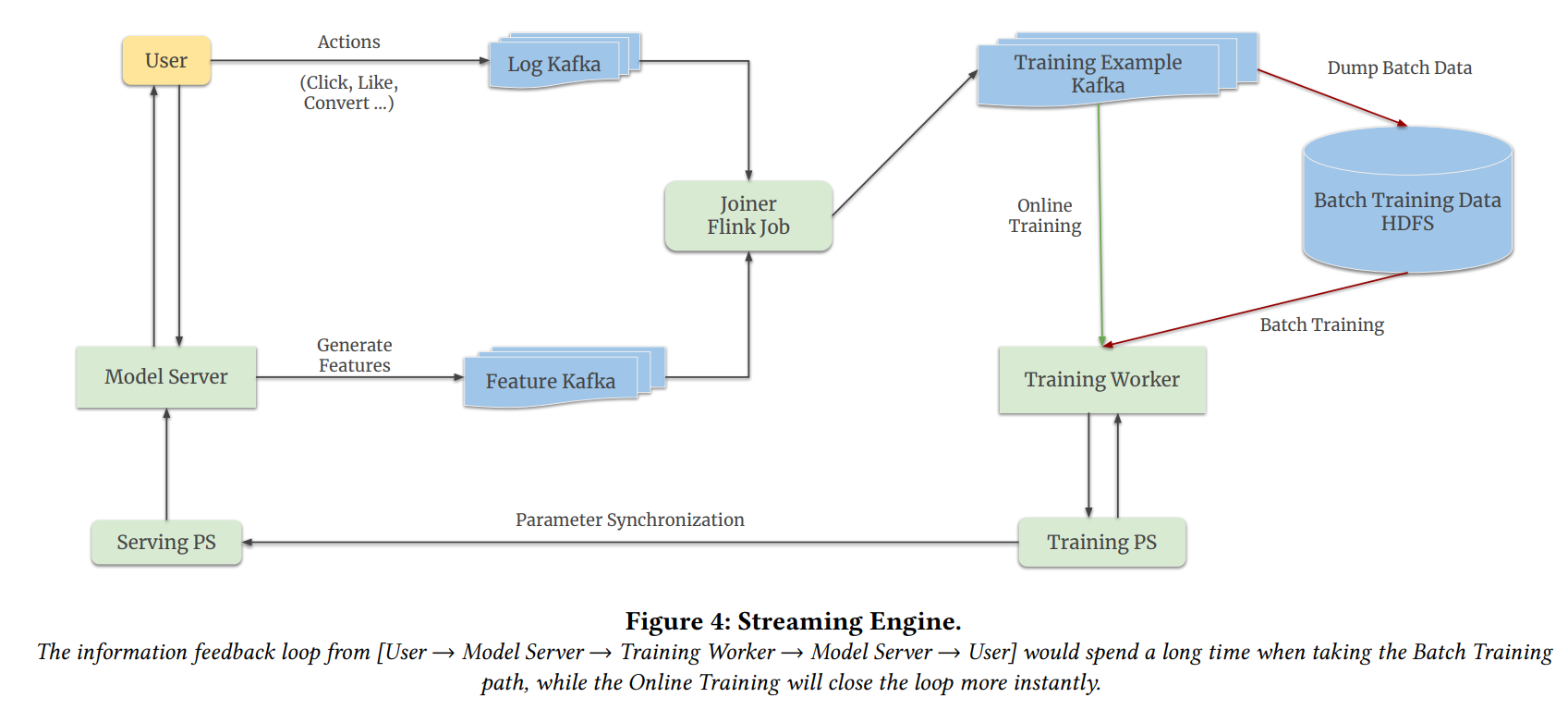 온라인 러닝에 사용되는 스트리밍 엔진의 아키텍쳐 도면.
온라인 러닝에 사용되는 스트리밍 엔진의 아키텍쳐 도면.
Engineering Details
지금까지 Monolith의 하드웨어 아키텍처를 알아보았다. 이제부터는 사용자 경험에 영향을 줄 수 있는 엔지니어링 요소 몇 가지를 소개하고, 바이트댄스 팀이 최종적으로 어떤 구성을 선택하였는지를 설명한다.
Parameter Synchronization
우선 온라인 러닝이 정말로 추천 성능 향상에 도움을 주는지를 검증한다.
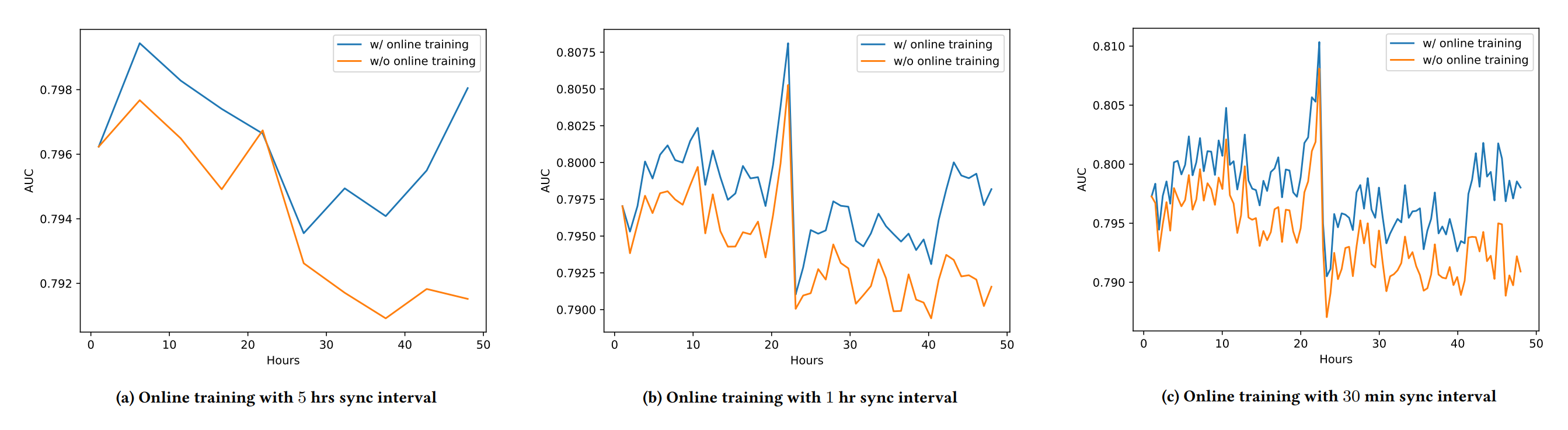 온라인 러닝 사용의 합리성을 도출한 실험. 7일간의 광고 데이터를 담은 Criteo 데이터셋을 시간순으로 잘라, 처음 5일간의 데이터로 모델을 훈련하고 그 다음 2일동안의 데이터로 온라인 러닝을 모방하여 실험한다. 온라인 러닝을 적용한 그래프는 파란색이고, 적용하지 않은 그래프는 노란색이다. 거의 대부분의 경우 온라인 러닝을 적용했을 때 추천 성능이 향상됨을 확인할 수 있다. 차트 A, B, C는 각각 5시간, 1시간, 30분 간격으로 온라인 러닝 파라미터 업데이트를 적용했을 경우의 실험 결과이다.
온라인 러닝 사용의 합리성을 도출한 실험. 7일간의 광고 데이터를 담은 Criteo 데이터셋을 시간순으로 잘라, 처음 5일간의 데이터로 모델을 훈련하고 그 다음 2일동안의 데이터로 온라인 러닝을 모방하여 실험한다. 온라인 러닝을 적용한 그래프는 파란색이고, 적용하지 않은 그래프는 노란색이다. 거의 대부분의 경우 온라인 러닝을 적용했을 때 추천 성능이 향상됨을 확인할 수 있다. 차트 A, B, C는 각각 5시간, 1시간, 30분 간격으로 온라인 러닝 파라미터 업데이트를 적용했을 경우의 실험 결과이다.
그렇다면 Training PS의 값을 Serving PS에 얼마나 자주 전달해야 할까? 물론 가능한 만큼 자주 전달하는 것이 좋다! 이 또한 실험을 통해 검증되었다.
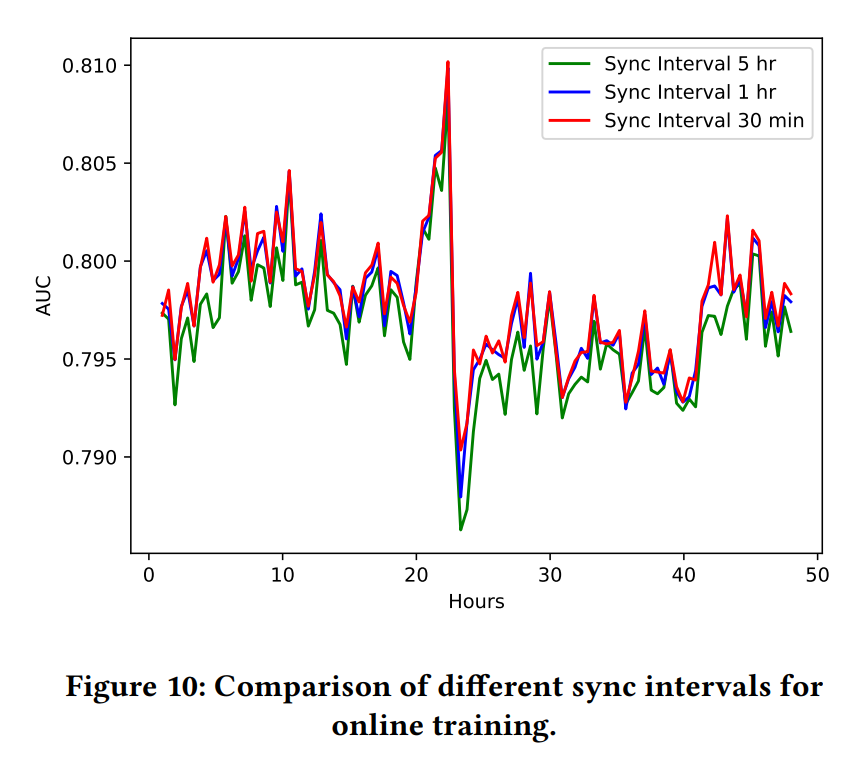 온라인 러닝에서 파라미터 Sync 간격의 중요성을 보여주는 실험. 바로 위의 차트와 동일한 실험이다. 가장 짧은 Sync 간격인 빨간색 그래프가 가장 좋은 추천 성능을 보여준다. 반면 가장 긴 Sync 간격인 초록색 그래프의 추천 성능은 나머지 그래프보다 아래쪽에 나타난다.
온라인 러닝에서 파라미터 Sync 간격의 중요성을 보여주는 실험. 바로 위의 차트와 동일한 실험이다. 가장 짧은 Sync 간격인 빨간색 그래프가 가장 좋은 추천 성능을 보여준다. 반면 가장 긴 Sync 간격인 초록색 그래프의 추천 성능은 나머지 그래프보다 아래쪽에 나타난다.
하지만 대규모 머신러닝 서비스의 모델 크기는 테라바이트 단위까지 올라가기 때문에 그 과정이 매우 느리고 큰 비용이 뒤따르기에, 철저한 손익 계산과 효율적인 엔지니어링이 필요하다. 다음 사실에 주목해보자.
Facts.
- Sparse Embedding이 모델의 용량 대부분을 차지한다.
- Sparse Embedding은 짧은 시간 안에 아주 작은 부분집합만이 업데이트된다.
- Dense Embedding은 Sparse Embedding보다 값의 변화가 매우 느리다. 즉 Gradient의 크기가 작다.
Derivations.
- Sparse Embedding은 자주 업데이트해도 비용이 크지 않다. 따라서 최대한 자주 업데이트한다.
- 가성비를 따져 보았을 때, 1분에 1번 업데이트 하는 것으로 결정.
- Dense Embedding은 어차피 Gradient의 크기가 작아서 자주 업데이트할 필요가 없다.
- 하루에 한 번, 트래픽이 작을 때 업데이트한다.
Hash Collision
트래픽이 큰 서비스의 User/Item 숫자는 예측할 수 없으며 이론상 무한한데, 이것을 유한한 컴퓨팅 자원으로 관리하기 위해 해시맵(HashMap)이 자주 사용된다. 해시 함수(Hash Function)의 정의역은 무한하지만 치역은 유한하기 때문이다. 따라서 대규모 추천 서비스에서는 User/Item ID를 그대로 사용하는 것이 아니라 한 번 해싱한 뒤에, Lookup Table에서 해당하는 Embedding을 가져오는 방식으로 사용한다.
여기서 문제가 발생한다. 해시맵은 필연적으로 충돌(Collision)을 일으킬 수밖에 없다. 즉, 일부 사용자들은 Embedding을 공유하게 된다. 이것은 추천 모델의 성능 저하를 일으킨다!
따라서 Monolith에서는 Collision이 없는 해싱 기법을 사용한다. 본 논문에서는 여러 가지 Collision-free 해싱 기법 중, 뻐꾸기 해싱(Cuckoo Hashing)이라고 불리는 알고리즘을 활용하여 모든 User/Item의 Embedding을 모델링하였다.
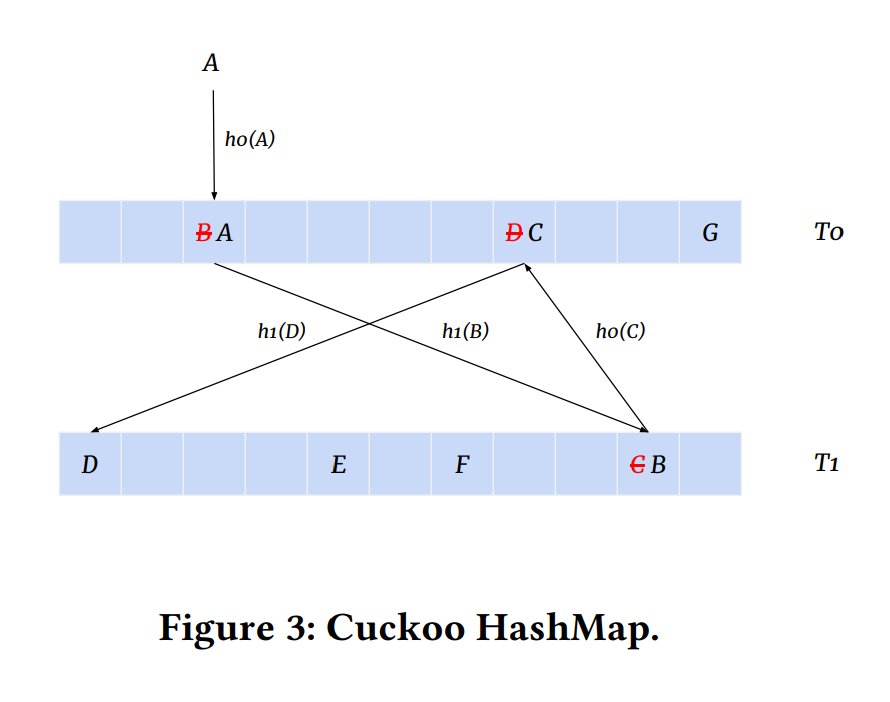 뻐꾸기 해시맵의 도표. 뻐꾸기 해싱에서는 두 개의 해시맵과 두 개의 해시 함수를 사용하고, 이미 데이터가 존재하는 버킷에 새로운 데이터가 들어오면, 기존의 데이터를 (마치 뻐꾸기가 남의 새끼를 둥지에서 밀어내듯이)반대쪽 테이블로 밀어낸다. 무한 루프가 생성되거나 load factor가 커질 경우에는 리해싱이 발생한다.
뻐꾸기 해시맵의 도표. 뻐꾸기 해싱에서는 두 개의 해시맵과 두 개의 해시 함수를 사용하고, 이미 데이터가 존재하는 버킷에 새로운 데이터가 들어오면, 기존의 데이터를 (마치 뻐꾸기가 남의 새끼를 둥지에서 밀어내듯이)반대쪽 테이블로 밀어낸다. 무한 루프가 생성되거나 load factor가 커질 경우에는 리해싱이 발생한다.
단, Collision-free해싱을 사용하는 만큼 더 많은 Embedding을 기억해야 하므로, 메모리 사용량이 더 커진다. 다음 사실에 주목해보자.
Facts.
- User/Item ID는 롱테일 분포를 그린다. 즉, 자주 등장하는 ID만 자주 등장하고, 절대 다수는 빈도수가 매우 낮다.
- 오래 전에 등장하고 더 이상 등장하지 않는 ID들은, 이미 존재하지 않거나 가치를 잃어버린 User/Item일 수 있다(e.g. 회원탈퇴, 앱 삭제, 한물간 트렌드 등).
Derivations.
- 입력받는 모든 Embedding을 기억하지 않고, 필터링 조건에 따라 상호작용 데이터를 무시한다.
- 1차 Filter : 빈도수가 높은 Embedding만을 기억한다. Threshold는 조정 가능한 Hyperparameter이다.
- 2차 Filter : 확률적으로 기억한다(e.g. 75% 확률로 Embedding 기억, 25%확률로 Drop). 여기에 사용되는 확률 또한 조정 가능한 Hyperparamter이다.
- 일정 시간이 지나도 재등장하지 않는 ID는 해시맵에서 제거한다.
- Expire Time 역시 조정 가능한 Hyperparamter이다.
아래 실험들을 통해 해시 충돌이 추천 성능에 미치는 영향을 살펴볼 수 있다.
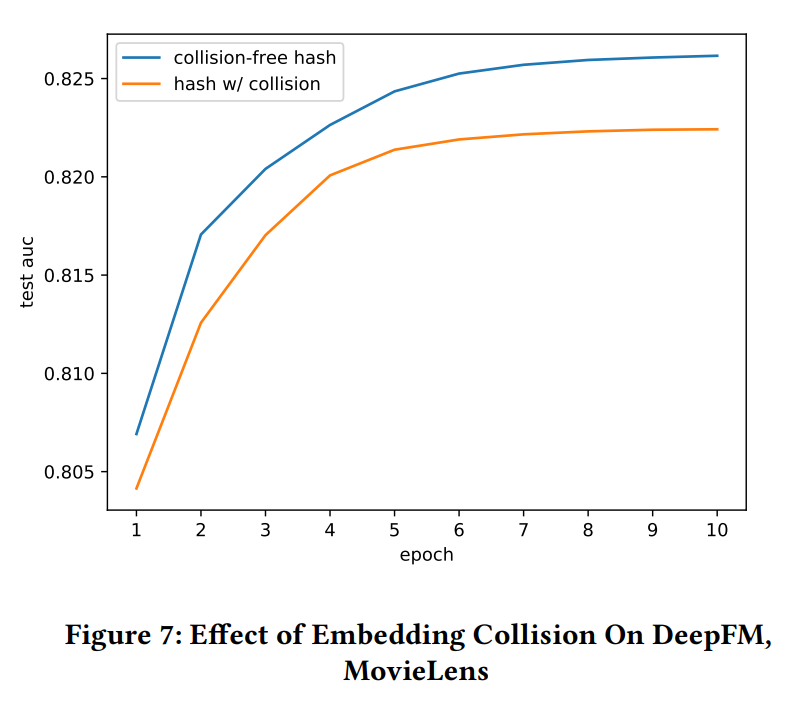 MovieLens 25M 데이터셋을 이용해 DeepFM을 10 에폭만큼 훈련시켰을 때의 AUC를 비교한다. Ratings이 3.5 이상인 샘플을 Positive, 3.5 미만인 샘플을 Negative로 간주한다. 파란색 그래프 : User/Item ID 해싱 없이 그대로 훈련시킨 경우. 빨간색 그래프 : User/Item ID에 MD5 해싱을 적용한 뒤 더 작은 ID space에 맵핑해 의도적으로 해시 충돌을 발생시킨 데이터로 훈련시킨 경우. 충돌이 없는 경우가 확연히 추천 성능이 높으며, Data Sparsity로 인한 오버피팅도 없음을 확인할 수 있다.
MovieLens 25M 데이터셋을 이용해 DeepFM을 10 에폭만큼 훈련시켰을 때의 AUC를 비교한다. Ratings이 3.5 이상인 샘플을 Positive, 3.5 미만인 샘플을 Negative로 간주한다. 파란색 그래프 : User/Item ID 해싱 없이 그대로 훈련시킨 경우. 빨간색 그래프 : User/Item ID에 MD5 해싱을 적용한 뒤 더 작은 ID space에 맵핑해 의도적으로 해시 충돌을 발생시킨 데이터로 훈련시킨 경우. 충돌이 없는 경우가 확연히 추천 성능이 높으며, Data Sparsity로 인한 오버피팅도 없음을 확인할 수 있다.
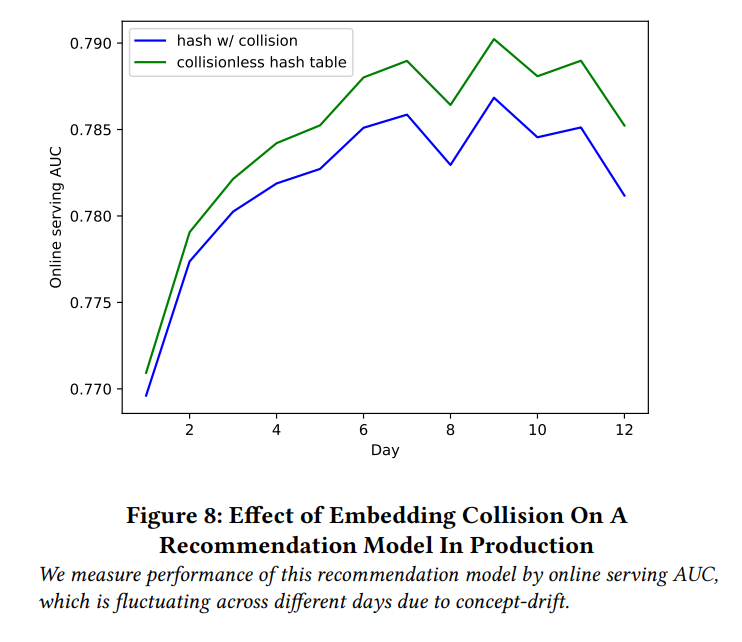 실제 ByteDance에서 동작 중인 서비스에서 실시간 A/B 테스팅으로 Collisionless Hash Table의 성능을 비교하였다. 파란색 그래프 : 해싱을 통해 ID공간을 2^48에서 2^25로 줄인 경우의 AUC. 초록색 그래프 : Collision-free 해싱과 필터링 규칙을 적용했을 때의 AUC. Collision이 없는 경우가 확연히 추천 성능이 높으며, 그래프의 추이도 큰 변화 없이 따라가는 것을 확인할 수 있다. 이는 일부 데이터를 버렸음에도 불구하고 알고리즘이 컨텐츠 트렌드의 변화를 여전히 잘 캐치했음을 뜻한다.
실제 ByteDance에서 동작 중인 서비스에서 실시간 A/B 테스팅으로 Collisionless Hash Table의 성능을 비교하였다. 파란색 그래프 : 해싱을 통해 ID공간을 2^48에서 2^25로 줄인 경우의 AUC. 초록색 그래프 : Collision-free 해싱과 필터링 규칙을 적용했을 때의 AUC. Collision이 없는 경우가 확연히 추천 성능이 높으며, 그래프의 추이도 큰 변화 없이 따라가는 것을 확인할 수 있다. 이는 일부 데이터를 버렸음에도 불구하고 알고리즘이 컨텐츠 트렌드의 변화를 여전히 잘 캐치했음을 뜻한다.
Fault Tolerance
Monolith에서는 오류로 인해 모델이 에러를 내뿜으면 자동적으로 모델을 재시작한다. 이런 경우 일반적인 해법은 모델의 상태를 주기적으로 스냅샷(Snapshot)하여 저장하고, 에러 시에 마지막 스냅샷으로부터 모델을 불러오는 것이다. 이 전략에는 두 가지 약점이 있다.
- 아무리 가장 최근의 Snapshot을 불러와도 약간의 데이터 손실이 발생한다.
- 테라바이트 단위의 모델을 스냅샷하는 것은 비싸다!
본 논문에서는 이 부분에 대해서 따로 실험을 진행하지는 않고, 다음과 같은 논리 하에 하루에 한 번씩 데이터를 백업하는 것이 합리적이라고 결론지었다.
“파라미터 서버가 1,000개 머신에 분산되어 있고 매일 스냅샷을 남긴다고 하자. 단일 머신의 고장률이 0.01%일 때, 10일에 1번 꼴로 머신 하나의 1일간의 파라미터 업데이트가 유실된다. 일간 활성 고객수가 1,500만명이라고 가정하면, 10일에 1번씩 15,000명의 고객으로부터 발생하는 1일간의 데이터를 잃는 것이다. 이것은 충분히 감수할 만하다…”“Suppose a model’s parameters are sharded across 1000 PS, and they snapshot every day. Given 0.01% failure rate, one of them will go down every 10 days and we lose all updates on this PS for 1 day. Assuming a DAU of 15 Million and an even distribution of user IDs on each PS, we lose 1 day’s feedback from 15000 users every 10 days. This is acceptable…”
즉, 해당 안건은 주어진 서비스와 인프라의 여러 가지 여건을 고려해서 적절히 결정하면 되겠다.
Conclusion
아키텍처 파트
- 분산 컴퓨팅이 기본이다.
- 파라미터 서버를 활용하라.
- 훈련/서빙에 사용되는 워커/파라미터 서버를 분리하라.
실험 파트
- 실시간 학습은 추천 성능의 향상을 불러온다.
- 파라미터 동기화는 자주 할수록 추천 성능이 향상된다.
- 해시 충돌은 추천 성능을 저하시킨다.
- 모든 임베딩을 하나하나 모델링하지 마라. 추천 성능에 큰 영향이 없다.
- 백업은 생각보다 자주 하지 않아도 된다.
External References
실시간 추천엔진 머신한대에 구겨넣기
Monolith: Real Time Recommendation System With Collisionless Embedding Table
Nonuniform Negative Sampling and Log Odds Correction with Rare Events Data
Factorization Machines
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!