[추천시스템 논문 리뷰] Wide & Deep Learning for Recommender Systems
Prerequisites
- Factorization Machines
Context
- Factorization Machine(2010)이 선형 모델과 Matrix Factorization의 결합이라면, Wide&Deep(2016)의 경우는 선형 모델과 딥러닝의 결합이라고 할 수 있다.
- 이후 Wide&Deep의 컨셉을 계승하고 강화한 DeepFM(2017)이 등장한다. 해당 논문에서는 선형모델과 딥러닝의 결합이라는 컨셉은 유지되지만, 이름처럼 딥러닝의 요소가 강화되었다.
- 이후 딥러닝을 이용한 추천 시도는 Neural Collaborative Filtering(2017) 으로 이어지게 된다. 해당 논문에서는 Wide&Deep 에서 선보인 딥러닝과 선형모델의 결합이 아닌, 순수한 딥러닝으로 추천을 시도하는 모습을 볼 수 있다.
Contributions
- 논문에서는 Memorization과 Generalization이라는 척도를 정의한다.
- Memorization은 기존에 사용자가 좋아했던 정보를 바탕으로 유사한 데이터를 계속 추천해주는 것이라고 할 수 있으며,
- Generalization은 두 개 이상의 과거 데이터를 결합해 학습데이터에 없는 새로운 상품을 추천하는 것이다.
- 본 논문에서 선보이는 Wide&Deep은 두 Part로 구성된다. 해당 모델에서는 선형 모델인 Wide Part로 Memorization을 확보하고, 잠재요소를 학습할 가능성이 있는 Deep Part로 Generalization을 확보하고자 한다.
Proposed Model
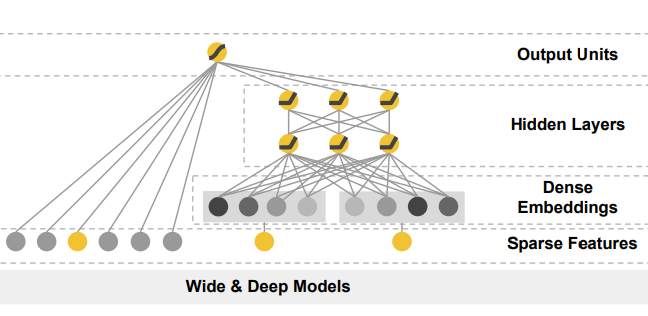
입력 벡터
본 논문에서 입력 벡터는 ${\bf x} =[x_1, \dots, x_n]$로 표시되며, Factorization Machines에서와 같이 각종 Feature 데이터를 포함할 수 있다. Wide Part와 Deep Part에 어떤 Feature를 흘려보낼지는 설계에 달렸지만, 해당 논문에서는 Wide Part에 Cross-Product Transforms를, Deep Part에는 Dense Features와 Categorical Features를 투입하였다.
💡 Cross-Product Transforms- 논문에서 계속 언급되는 CPT는 Feature Engineering을 통해 뽑아낸 Feature들을 가리킨다고 이해하면 된다. 가령 $ \text{(Genre==SF)&(year≤2000)} $ 와 같은 CPT를 적용했을 경우, 스타워즈는 1의 값을 가지게 되고, 로마의 휴일은 0의 값을 가지게 된다.
- 결과적으로 해당 논문에서는 이러한 방식을 채택한 모델로 성능 향상을 이루어냈지만, 인간을 통한 Feature Engineering이 필요하다는 약점이 생겼다. 이것은 화웨이에서 발표한 정신적 후속 논문 DeepFM에서 보완된다.
Wide Part
입력벡터 $ {\bf x_{\text{wide}}} =[x_{\text{wide}_1}, \dots, x_{\text{wide}_n}] $에 대한 선형 모델로, $y={\bf w_{\text{wide}}^{\it \text{T}} x_{\text{wide}}}+b$로 적을 수 있다. ${\bf w_{\text{wide}}}=[w_{\text{wide}_1}, \dots, w_{\text{wide}_n}]$과 $b\in\mathbb{R}$을 파라미터로 가진다. 최종 출력값은 스칼라값이다.
Deep Part
입력벡터 ${\bf x_{\text{deep}}} =[x_{\text{deep}_1}, \dots, x_{\text{deep}_n}]$에 대한 딥러닝 모델로, 활성화 함수를 사용한 Fully-Connected Layer를 연속적으로 이어붙인 구조이다. $l+1$번째 Layer는 다음과 같이 표현된다.
\[\begin{align*} a^{(l+1)} &= f(W^{(l)}a^{(l)}+b^{(l)})\\ a^{(l)}&=\text{activation at layer }{\it l}\\b^{(l)}&=\text{bias at layer }{\it l}\\W^{(l)}&=\text{weights at layer }{\it l}\\f&=\text{activation function (e.g. ReLU)}\end{align*}\]마지막 ReLU의 출력값은 선형모델을 거쳐 스칼라값으로 변환된다. 이는 $y={\bf w_{\text{deep}}^{\it \text{ T}} {\it a}^{({\it l}_{final})}}+b$로 적을 수 있으며, ${\bf w_{\text{deep}}}=[w_{\text{deep}_1}, \dots, w_{\text{deep}_n}]$을 파라미터로 가진다. 최종 출력값은 스칼라값이다.
💡 Handling Categorical Features
모든 Feature가 Dense하다면 좋겠지만 현실은 그렇지 않다. Categorical Features의 경우 는 0과 1로 이루어지며, 대다수 항목이 0인 Sparse Binary Vector이다. 이에 대응해 논문에서는 각 Categorical Feature마다 Embedding 레이어를 두어, Sparse Feature를 Dense Embeddings으로 바꾸고, 모든 Embedding과 Dense Features를 concat하여 새로운 입력 벡터를 만든다.Combining Wide & Deep Outputs
Wide&Deep의 최종 predictor는 Wide Part와 Deep Part의 출력값의 합으로 구성된다.
\[P(Y=1|{\bf x}) = \sigma({\bf w}^{T}_\text{wide}[{\bf x}, \phi({\bf x})]+{\bf w}^{T}_\text{deep}a^{(l_{final})}+b)\]마지막으로 Label은 사용자 행동을 나타낸다. 가령 논문에서 진행한 Google Play Store에서의 실험에서는 사용자가 앱을 클릭했는지의 여부를 0과 1로 나타낸 것이 Label로 사용되었다. Label이 이진변수이므로, Predictor 역시 0과 1사이의 값으로 변환해 주는 과정이 필요하다. 이 때문에 Logistic Sigmoid가 수식에 들어가게 된다.
Model Learning
최종 Predictor와 Label로부터 산출된 Logistic Loss를 이용하여 Wide Part와 Deep Part를 동시에 학습한다. 앙상블 방법과는 차이가 있음을 유의하자. Deep Part는 역전파 알고리즘으로 학습하며, Wide Part는 FTRL(Follow the Regularized Leader) 알고리즘으로 학습한다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!