[DL Book] 11.1. Evaluation Metrics
우리는 두 가지를 결정해야 한다.
- 어떤 성능 평가 지표를 사용할 것인가?
- 얼마나 낮은 값을 원하는가?
목표값 설정
대부분의 경우 오차율을 0까지 끌어내리는 것은 불가능하다.
베이즈 오차 (Bayes error, Irreducible error)
베이즈 오차는 훈련 데이터가 무한히 많이 있다고 해도 절대로 줄일 수 없는 오차를 말한다. 훈련 데이터의 특징(feature)이 데이터를 설명하기 불충분하거나, 데이터 자체가 확률적 노이즈를 포함하는 것 등이 베이즈 오차를 발생시키는 원인이다.제한된 데이터
훈련 데이터의 양이 무한하지 않다는 사실도 베이즈 오차의 원인이 된다. 대부분의 기계학습 모델이 데이터가 많아지면 더 잘 작동하는 것은 사실이다. 하지만 데이터를 추가적으로 수집할 때 발생하는 비용과, 그로 인한 성능 개선을 비교하고 추가 수집을 진행해야 한다. 특히 데이터를 수집하려면 돈, 시간, 인간의 생명 등이 소모되는 일부 도메인에서는 원하는 대로 데이터를 수집할 수 없을 것이다.
그렇다면 어떤 값을 목표로 삼아야 할까? 학술적인 환경에서는 이전 연구에 사용된 벤치마크 결과를 참고해 목표값을 설정할 수 있다. 현실적인 문제를 해결할 때는, 머신러닝 시스템의 이용자가 불편을 느끼지 않을 정도의 수치를 목표로 삼을 수 있다.
평가 지표 설정
평가 지표(Performance metric)는 모델이 얼마나 잘 동작하는지 측정하기 위한 것으로, 오차함수와는 별개의 것이다. 대표적인 평가 지표로 오차율(Error Rate)이 있다. 하지만 현실적인 문제를 풀 때는 더 복잡한 평가 지표를 사용할 필요가 있다.
단적인 예로 False Negative와 False Positive의 비용이 다른 경우가 있다. 암이 없는 환자를 암 환자로 오진했을 때와, 암 환자를 암이 없다고 오진했을 때의 비용 차이는 너무나 크다. 이런 경우 오차율로 모델을 평가한다면 어떻게 될까? 10,000명 중 1명이 암 환자라면, 머신러닝 모델은 단순히 모든 환자를 “암이 없는 환자”로 평가하도록 학습할 것이고, 0.01%의 오차율이라는 우수한(?) 결과를 내놓을 것이다.
따라서 오차율은 이 문제를 풀기 위해서 적절한 평가 지표가 아니다. 이런 경우에는 정밀도(Precision)와 재현율(Recall)을 사용하는 것이 좋다. 지표로써 하나의 숫자가 필요하다면 F1 Score를 사용할 수 있다.
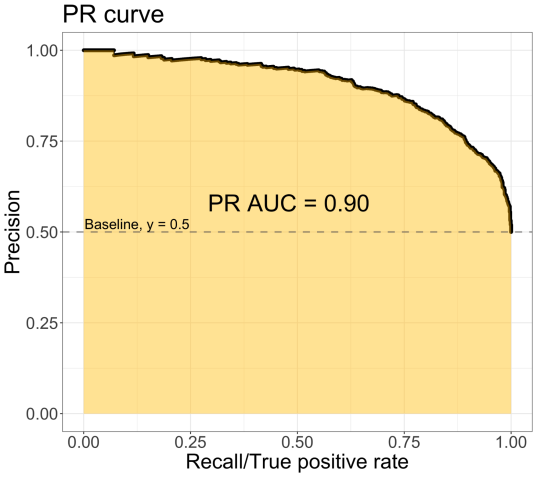
\[\begin{align*} \text{Precision} &= \frac{\big|\text{Correctly Predicted Events}\big|}{\big|\text{Reported Events}\big|}\\ \text{Recall} &= \frac{\big|\text{Correctly Predicted Events}\big|}{\big|\text{All Events}\big|}\\ \text{F1 Score} &= \hspace{0.5cm} \frac{\text{2 * Precision * Recall}}{\text{Precision + Recall}} \end{align*}\]정밀도와 재현율은 일반적으로 Trade-off 관계에 있다. 예를 들면 이진 분류기의 경우, 분류의 기준이 되는 경계값을 변동시킴으로써 정밀도와 재현율을 조정할 수 있다.
 출처 : https://neptune.ai/blog/how-to-test-recommender-system
출처 : https://neptune.ai/blog/how-to-test-recommender-system
이러한 시행의 결과를 요약한 정밀도-재현율 곡선(Precision-Recall Curve)이 자주 사용되며, 이 곡선 아래의 넓이를 계산한 AUC(Area Under the Curve) 지표도 자주 사용된다.
커버리지(Coverage)
일부 머신러닝 시스템에서는 추론 결과의 신뢰도가 낮다고 판단할 때 추론을 거부할 수 있다. 이 경우, 해당 입력에 대한 값은 인간이 직접 입력해야 한다. 그런데 거의 모든 입력에 대해 추론을 거부한다면 높은 정확도를 달성할 수 있다. 그러나 이는 머신러닝 모델이 해당 문제를 잘 해결한다는 것은 아니다. 이런 상황에는 커버리지(Coverage)라는 지표를 도입할 수 있다. 커버리지는 주어진 입력에 대해 머신러닝 모델이 결과를 제출할 수 있는 입력의 비율이다.
\[\text{Coverage} = \frac{\big|\text{Inputs the model can respond to}\big|}{\big|\text{All inputs}\big|}\]정밀도와 재현율의 관계와 비슷하게, 커버리지는 정확도와의 Trade-off가 가능하다.
지금까지 소개한 것들 이외에도 수많은 평가 지표가 존재한다(i.e. 클릭율, 유저 설문조사 반응 등…) 중요한 것은 모델 개선을 본격적으로 시작하기 전에 어떤 평가 지표를 사용할지 잘 선택하고, 그 평가 지표를 개선하는 데에 집중하는 것이다. 목표가 명확히 설정되지 않으면 시스템 개발이 원활히 진행될 수 없다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!