[DL Book] 11.3. Determining Whether to Gather More Data
대부분의 경우 데이터를 더 모으는 것은 모델 성능의 개선으로 이어진다. 하지만 과연 데이터를 더 모은다고 해서 모든 일이 해결될까? 데이터를 모으는 것만이 유일한 해법은 아니기에, 우리는 데이터 수집에 들어가는 비용과 그 효용성을 저울질할 필요가 있다.
무작정 데이터를 탓하지 마라
데이터가 더 필요한지 확인하려면, 학습 데이터셋에 대해서 모델이 좋은 성능을 내는지 조사하라. 테스트 데이터셋은 고사하고 학습 데이터셋에 대해서 좋은 성능을 내지 못한다면, 모델이 학습 데이터를 온전히 활용하고 있지 못하다는 뜻이다. 따라서 이런 경우에는 무작정 데이터를 더 수집하기보다는 모델을 개선해야 한다. 예를 들면 더 깊은 심층 신경망을 사용하거나, 초매개변수를 조정할 수 있다.
올바른 초매개변수를 선택하고 수용력을 극대화한 모델조차 학습 데이터셋을 활용하는 데에 실패한다면, 이제는 데이터의 질이 문제일 수 있다. 노이즈가 너무 많거나, 레이블링이 잘못되었을 수 있다. 이럴 경우에는 처음부터 다시 시작하는 수밖에 없다. 더 정확한 데이터를 모으거나, 더 많은 특징(feature)을 사용해야 한다.
일반화 능력 부족
만약 모델이 학습 데이터셋에 대해 좋은 성능을 내지만, 테스트 데이터셋에 대해서는 그렇지 못할 경우, 일반화 능력의 부족으로 볼 수 있다. 이 경우 두 가지 전략을 선택할 수 있다.
- 모델을 개선한다. 학습 데이터에 대해서 좋은 성능을, 테스트 데이터에 대해서 나쁜 성능을 내는 것은 과적합(Overfitting)에 해당한다. 따라서 모델의 수용력을 줄이거나, 정칙화 전략을 사용할 수 있다. 정칙화 전략에 대해서는 같은 책의 7장을 참고하면 좋다.
- 데이터를 더 모은다.
- 이 경우 데이터를 수집할 때 소모되는 비용을 고려하여 결정을 내려야 한다. 단적인 예로, 웹사이트를 운영하는 회사에서 접속 기록을 수집하는 것은 어렵지 않지만, 심장질환 환자의 부검 결과를 손에 넣는 것은 훨씬 어려울 것이다.
또한 데이터를 얼마나 더 모을지 결정하는 것도 중요하다. 이런 경우 학습 데이터셋의 크기와 모델 성능을 비교한 도표를 그려 보면 대략적인 예측에 도움이 된다.
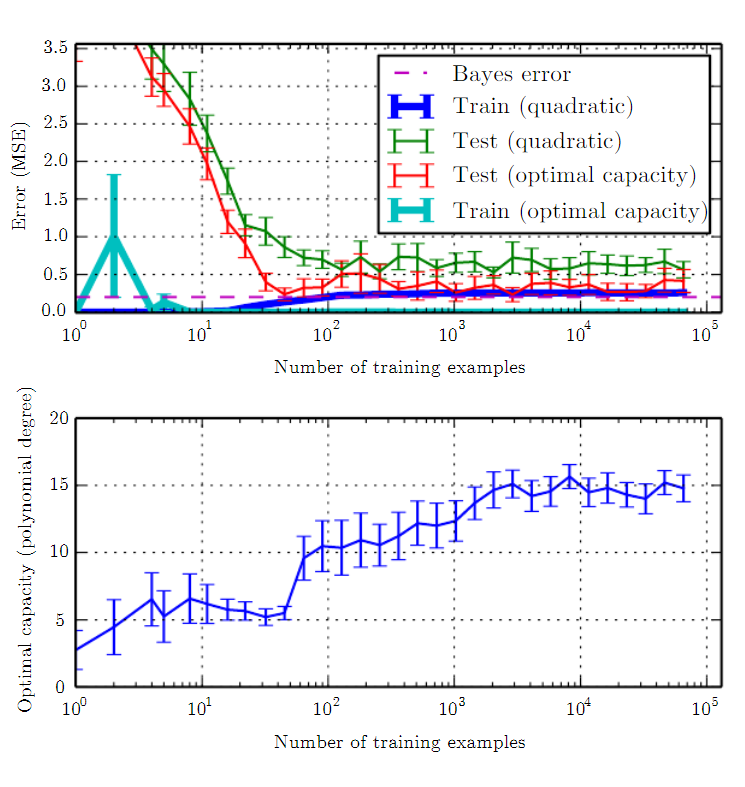 학습 데이터셋의 크기와 모델 성능을 기록한 도표. 학습 데이터의 크기는 로그 스케일(log-scale)로 잡는 것이 좋다.
학습 데이터셋의 크기와 모델 성능을 기록한 도표. 학습 데이터의 크기는 로그 스케일(log-scale)로 잡는 것이 좋다.
미미한 양의 추가 데이터는 성능에 크게 영향을 주지 않기 때문이다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!