[DL Book] 11.4. Selecting Hyperparameters
대부분의 딥러닝 알고리즘은 학습 알고리즘으로는 알아낼 수 없는 초매개변수를 동반한다. 초매개변수들을 어떻게 설정하느냐에 따라 모델의 성능은 천차만별이기에, 이를 올바르게 설정하는 것이 중요하다.
초매개변수는 수동으로 설정하거나 자동 탐색을 통해 찾아낼 수 있다. 전자는 알고리즘에 대한 수학적 이해가 필요하며, 후자는 비교적 이해가 부족해도 진행할 수 있지만 월등히 많은 컴퓨팅 자원과 시간이 필요하다.
수동으로 설정하기
초매개변수 탐색의 목적은 모델의 표현력(Representational Capacity)을 실제 풀고자 하는 문제의 알려지지 않은 복잡도와 일치하도록 만드는 것이다. 여기서 표현력이란 우리가 흔히 아는 모델의 수용력(Capacity)를 포함하지만 다른 개념으로, 학습 알고리즘이 최적화 점에 도달할 수 있는지의 여부, 그리고 정칙화가 얼마나 적용되었는지 등을 포함한다. 기본적으로 모델의 수용력이 높다면 표현력이 높지만, 정칙화와 학습 알고리즘의 선택에 따라 존재하는 모든 함수를 근사할 수는 없다.
U-shaped curve를 통한 초매개변수 탐색
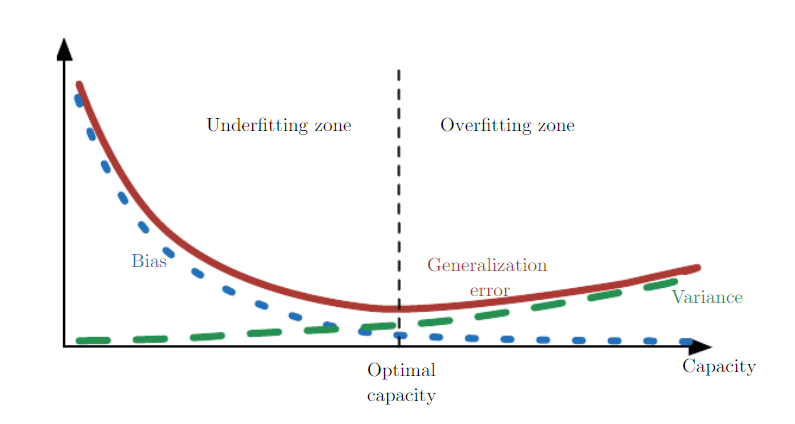
위 도표는 머신러닝 모델의 수용력과 일반화 성능의 관계를 보여준다. 모델이 과적합(Overfitting) 혹은 과소적합(Underfitting)되었다고 판단된다면, 위 도표를 참고해 초매개변수를 조절하는 전략을 사용할 수 있다. 단, 이는 모델의 수용력과 직결되는 초매개변수의 경우에만 유효하다. 이와 같은 초매개변수에는 은닉층의 크기, 임베딩 차원의 크기 등이 있다.
💡 일부 초매개변수의 경우 U-shaped curve의 모든 지점을 탐색하는 것이 불가능하다.- 예를 들면 어떤 정칙화 항을 도입할 것인지, 말 것인지는 이진(binary) 자료형의 초매개변수로, 연속적이 아니라 이산적인 값이기 때문에 U-shaped curve의 모든 점을 탐색할 수 없다.
- 또한 정칙화 항의 계수($\alpha)$ 역시 $0<\alpha$를 만족해야 한다는 조건이 있기 때문에, 최솟값인 0 이하로 내려갈 수 없다. 이것은 모델이 과소적합되어 수용력을 늘리고 싶은 상황에서 $\alpha$가 이미 0이라면, 정칙화 항의 계수를 조절하는 것은 해법이 될 수 없다는 것을 의미한다.
학습률
학습률은 아마도 가장 중요한 초매개변수일 것이다. 만약 시간이 없어 단 하나의 초매개변수만 조절할 수 있다면, 학습률을 조정하라. 학습률은 모델의 표현력에 다른 초매개변수보다 복잡한 방식으로 영향을 끼친다.
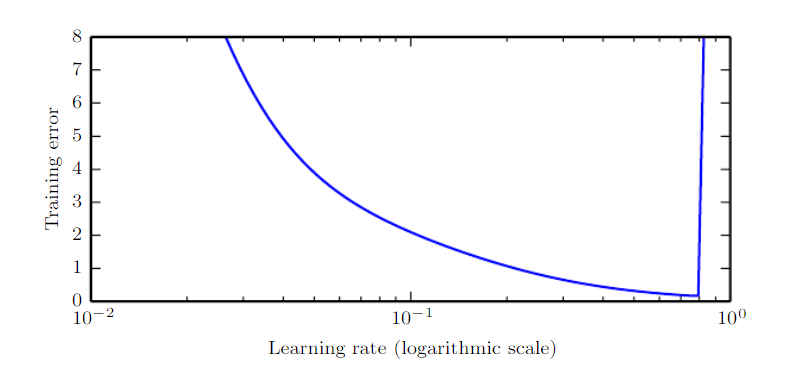
타 초매개변수가 모델의 일반화 성능에 대해 U-shaped curve를 그린다면, 학습률은 모델의 훈련 정확도에 대해 U-shaped curve를 그린다. 따라서 너무 크지도 작지도 않은 올바른 학습률을 설정하는 것은 매우 중요하다.
💡 학습률 크기에 따른 부작용- 학습률이 너무 크다면 목표로 하는 최소 지점을 지나쳐 반대 방향으로 향하는 경우가 있다. 이 경우 올바른 방향으로 이동했음에도 불구하고 오차가 증가할 수도 있다. 이것을 오버슈팅(Overshooting)이라고 한다.
- 학습률이 너무 작다면 국소적 최솟값(local minima) 혹은 안장점(saddle point)에 빠져 헤어나오지 못하는 경우가 생긴다.
자동 탐색을 통한 설정
많은 머신러닝 모델의 강력함은 초매개변수를 1~2개만 설정하는 것으로 좋은 성능이 나온다는 것이다. 반면 심층신경망의 경우 수십 개의 초매개변수를 다루는 경우도 있다. 이 경우 수작업으로 일일히 초매개변수를 탐색하는 것은 비효율적이다. 이럴 때에는 자동 탐색 알고리즘의 힘을 빌리는 방법이 있다.
자동 탐색 알고리즘은 목표값이 모델의 성능이고, 변수가 모델의 초매개변수인 또 하나의 최적화 과정으로 바라볼 수 있다. 불행히도, 이 최적화 역시 초매개변수 설정을 필요로 한다(i.e. 탐색할 범위 등). 하지만 이렇게 발생하는 2차적인 초매개변수는 도메인에 덜 구속되기에, 선택하기가 비교적 쉽다.
💡 모델 기반 초매개변수 탐색
- 최적화 문제인 만큼 그래디언트를 사용해 초매개변수를 찾아낼 수도 있다. 하지만 현실에서 이 그래디언트는 대부분 확보하기가 어렵다는 단점이 있다.
- 그래디언트를 사용하지 않는 방법으로는 베이지안(Bayesian) 모델링이 대표적이다. 초매개변수를 입력값으로, 검증 오차의 기댓값(Expectation)을 목표로 설정하여 회귀 문제를 푸는 것이다. 단, 베이지안 초매개변수 탐색은 안정성이 떨어지고, 데이터로 삼을 만큼 많은 학습 결과가 필요하다는 단점이 있다.
그리드 서치
3개 이하의 초매개변수에 대해서는 그리드 서치(Grid Search)를 이용하는 것이 대중적이다.
- 각 초매개변수마다 취할 수 있는 유한 개의 값을 포함하는 집합을 생성한다.
- 탐색에 사용되는 값의 범위는 과거에 진행된 연구 등에서 힌트를 얻어, 경험적으로 정한다. 즉 적당히 정한다.
- 탐색에 사용되는 값의 간격은 등차수열/등비수열로 정하거나, 지수적으로 정하거나, 로그 스케일로 정할 수도 있다.
- 모든 초매개변수들의 집합의 데카르트 곱(Cartesian Product)을 생성한다.
- 데카르트 곱의 모든 경우의 수를 실험하고 최고의 성능을 보이는 설정을 찾는다.
그리드 서치는 좋은 기법이지만 컴퓨팅 자원과 시간이 많이 소모된다는 명확한 단점이 존재한다.
랜덤 서치
그리드 서치는 이산적인 공간에서 진행된다. 초매개변수가 10개일 경우, 그리드 서치에는 9개의 초매개변수가 모두 동일하고 하나의 초매개변수에만 변화를 준 2개의 독립적인 학습 과정이 존재한다. 이것은 매우 비효율적이다. 반면 랜덤 서치를 사용할 경우, 초매개변수를 확률분포에서 샘플링한다. 따라서 매번 조금이나마 다른 값으로 서치가 진행되기 때문에 버려지는 정보가 없다.
랜덤 서치는 초매개변수가 특정한 분포를 띠는 것을 가정하고 진행한다. 예를 들면 연속적인 공간의 초매개변수는 로그 균등분포(uniform distribution on a log-scale)를 사용하고, 이산적인 공간의 초매개변수는 베르누이 분포 혹은 멀티누이 분포를 사용할 수 있다. 예를 들면 학습률이라는 초매개변수를 설정한다면, 연속적인 공간의 초매개변수에 속하므로 다음과 같은 확률분포를 따른다고 가정할 수 있다.
\[\text{log_learning_rate} \sim u(-1, -5)\\ \text{learning_rate}=\text{10}^\text{log_learning_rate}\]이렇게 확률분포를 정의한 뒤에는 초매개변수의 값을 분포로부터 샘플링해 학습을 진행하고, 어떤 값이 최선의 성능을 내는지 비교할 수 있다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!