[DL Book] 7. Regularization for Deep Learning
정칙화의 개념
- 학습 데이터(Training data)뿐만 아니라 새로 들어오는 데이터(Test data)에도 모델이 좋은 예측을 할 수 있도록 학습 전략을 조정하는 것. 새로 들어오는 데이터에 대해서 정확도가 개선된다면, 학습 데이터에 대한 정확도를 조금 희생해도 좋다.
- 정칙화 전략은 다양하며, 현대 딥러닝에서 활발히 연구되는 분야 중 하나이다.
Bias-Variance Tradeoff
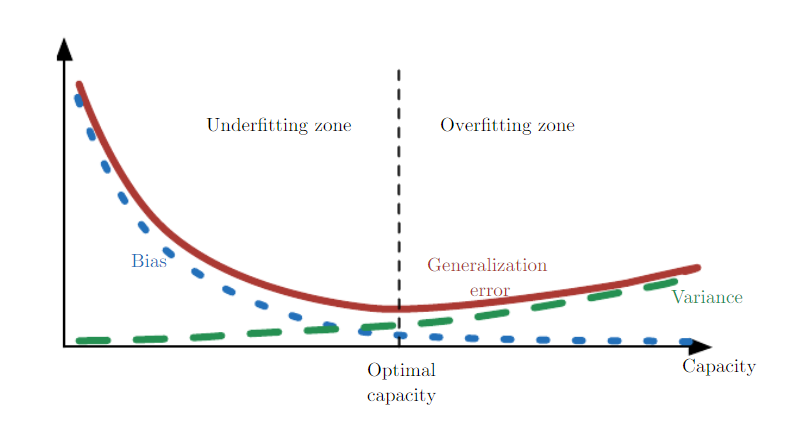
5장에서 살펴본 도표에서, 학습된 머신러닝 모델의 상태는 간단히 3종류로 나눌 수 있다.
- Underfitted : High Bias, Low Variance
- 모델이 표현하는 분포가 원본 데이터 분포를 포함하지 않는 상태
- Well-fitted : Low Bias, Low Variance
- 모델이 표현하는 분포가 원본 데이터 분포를 정확히 추정한 상태
- Overfitted : Low Bias, High Variance
- 모델이 표현하는 분포가 원본 데이터 분포를 포함하지만, 다른 데이터 분포도 포함하는 상태
💡 자세히 보기:정칙화의 목적은 Overfitted 상태의 모델을 Well-fitted 상태의 모델로 바꾸는 것이다.
모델 수용력 조절에 대한 실용적 접근
- 현실 세계의 응용에서는 매우 복잡한 모델을 만들었다고 해서 그 모델의 수용력이 충분한지는 알 수 없다. 원본 데이터 분포를 전혀 알 수 없는 경우가 많기 때문이다. 특히나 딥러닝의 경우 이미지, 음성 등 매우 복잡한 도메인의 데이터를 다루기에, 아무리 깊은 딥러닝 모델로도 수용할 수 없는 것이 당연할지도 모른다.
- 따라서 딥러닝 모델의 수용력을 조절해 성능을 극대화하고자 할 때, sweet spot을 찾고자 접근하는 것은 어렵다. 일반적으로, 수용력을 극대화한 모델을 고른 뒤 정칙화를 가해 학습시키는 것이 최선의 성능을 낸다.
무작정 층을 깊게 만들면 성능이 좋아진다는 우스갯소리의 기원이 바로 여기가 아닐까?
7.1. Parameter Norm Penalties
정칙화의 등장은 딥러닝 등장 이전으로 돌아간다. 선형회귀 및 로지스틱 회귀 등의 단순한 모델에서도 정칙화를 통해 그 효과를 누릴 수 있다. 많은 정칙화 전략은 모델의 수용력을 제한하는 방식으로 구현된다.
손실함수 $J$가 주어졌을 때, 그 함수에 정칙화 항(regularization term)을 더하는 것으로 정칙화를 실행할 수 있다. 정칙화된 손실함수는 $\tilde{J}$로 주어진다.
\[\tilde{J}(\theta;X,y)=J(\theta;X,y)+\alpha\Omega(\theta)\]여기서 $\alpha$는 값이 증가할수록 정칙화를 강하게 적용하는 초매개변수이다. 손실함수 $J$에 추가된 $\Omega(\theta)$가 바로 정칙화 항이며, 모델 파라미터 $\theta$에 대한 어떤 함수로 주어진다. 이번 장에서는 함수 $\Omega$의 특이한 케이스인, $\Omega$가 모델 파라미터 $\theta$에 대한 노름(Norm)과 유사하게 주어졌을 때를 살펴본다.
💡 자세히 보기:
- 정칙화 함수는 일반적으로 가중치(weights)에 대한 함수로 주어지며, 편향(bias)와는 무관하다. 이는 편향이 모델 학습에 미치는 영향이 가중치보다 작기 때문이다. 또한, 편향에 해당하는 파라미터까지 정칙화할 경우 모델이 underfitting될 가능성이 생긴다.
- 이제부터 가중치 파라미터와 가중치 및 편향 파라미터는 각각 $w$와 $\theta$로 구분한다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!
This post is licensed under CC BY 4.0 by the author.