[DL Book] 7-12. Dropout
7.12. 드롭아웃
드롭아웃(Dropout)은 심층신경망을 훈련할 때 무작위로 일부 경로를 누락시키는 정칙화 기법이다. 이는 7.5. Noise Robustness에서 소개한 은닉층별로 적용되는 노이즈의 곱셈이나, 7.11. 앙상블 기법에서 소개한 배깅의 특별한 경우로도 바라볼 수 있다.
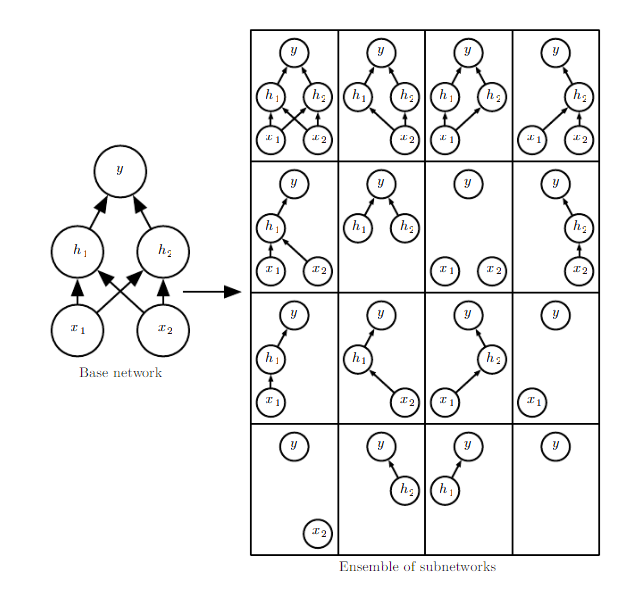
배깅과의 차이
일반적으로 배깅은 여러 개의 모델을 완전히 독립적으로 훈련시킨다. 심층신경망에서도 이런 방식이 유효하지만, 모델 크기가 매우 큰 신경망에서 이것은 비효율적이다. 드롭아웃은 은닉층의 일부 출력에 무작위로 0을 곱함으로써 여러 개의 모델을 구현한 것과 같은 효과를 누린다. 또한, 이것은 일반적인 배깅과 다르게 모든 모델이 파라미터를 공유(Parameter Sharing)하게 만드는 효과가 있다. 따라서 드롭아웃은 $n$개의 서로 다른 모델을 앙상블하는 배깅에 비해 엔지니어링적인 관점에서도 매우 효율적이다.
💡 자세히 보기
- 네트워크에서 노드를 제거하는 방법으로는 0을 곱하는 방법 외에도 무궁무진하다.
- 입력층에서 노드가 제거될 확률은 0.2, 은닉층에서 노드가 제거될 확률은 0.5를 > 사용하도록 책에서 권장하였다.
- 드롭아웃은 일반적으로 미니배치 경사하강법(Minibatch Stochastic Gradient Descent)와 함께 사용하게 된다. 이 경우, 배깅의 주요 포인트 중 하나인 “각 모델은 원본 데이터에서 일정 횟수 복원추출한 새로운 데이터셋으로 학습시킨다”를 만족함을 알 수 있다.
추론
드롭아웃을 적용해 훈련시킨 모델이 총 $n$개의 서로 다른 모델을 만들어냈다고 하자. 학습이 진행될 때마다 무작위로 노드를 탈락시키는 마스크(Mask) 벡터들의 집합을 $\mu_1, \dots, \mu_2 \in \boldsymbol \mu$라고 하면, 각 모델이 학습에 사용된 비율은 $p(\boldsymbol \mu)$라고 쓸 수 있다. 또 기존 모델이 $p(y|\boldsymbol x)$를 모델링한다고 하면, 무작위로 노드 탈락이 적용된 모델의 수식은 $p(y|\boldsymbol x, \boldsymbol \mu)$가 된다.
그렇다면 $p(y|\boldsymbol x, \boldsymbol \mu)$로 모델링된 모든 확률분포의 평균은 다음과 같다.
\[\sum_{\boldsymbol\mu}p({\boldsymbol \mu})p(y|\boldsymbol x, \boldsymbol \mu)\]하지만 이 수식은 약간의 단순화를 거치지 않고는 다루기 힘들다. 일반적인 평균 대신 조화평균을 사용하면 계산을 단순화할 수 있다. 다음 수식에서는 단순함을 위하여 $\boldsymbol \mu$는 균등분포임을 가정하였으며, $d$는 전체 네트워크에서 드롭아웃이 적용될 수 있는 노드의 숫자이다.
\[\tilde{p}_{ensemble(y|\boldsymbol x)}=\sqrt[2^d]{\prod_{\boldsymbol \mu}p(y|\boldsymbol x, \boldsymbol \mu)}\]마지막으로 이 수식이 올바른 확률분포를 표현하도록 정규화해 주자.
\[p_{ensemble(y|\boldsymbol x)}=\frac{\tilde{p}_{ensemble(y|\boldsymbol x)}}{\sum_{y'}\tilde{p}_{ensemble(y'|\boldsymbol x)}}\]Weight Scaling
이론적으로는 위 수식의 결과가 여러 모델이 나타내는 확률분포의 평균을 의미한다. 현실에서는 약간 다른, 일반적인 상황에서 이론적으로 검증되지는 않았지만 경험적으로 효과적이고 효율적인 트릭이 있다.
“모든 노드의 출력값에 그 노드가 네트워크에 포함될 수 있는 확률을 가중치로 곱한다.”
제프리 힌튼이 고안한 이 방식을 Weight Scaling Inference Rule이라고 부른다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!