[DL Book] 7-7. Multitask Learning
7.7. Multitask Learning
멀티태스크 러닝에서는 같은 입력 데이터를 가지고, 여러 개의 심층신경망을 이용해 여러 개의 문제를 동시에 푼다. 일반적으로는 두 개의 모델이 완전히 독립적으로 학습되겠지만, 멀티태스크 러닝의 핵심은 두 모델 사이에 일부 가중치를 공유하는 것이다.
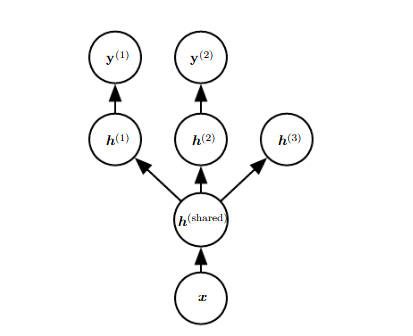
위 그림은 전형적인 멀티태스크 러닝의 예시이다. 동일한 입력 데이터 $\boldsymbol x$를 가지며, 풀고자 하는 문제에 따라 모델이 3갈래로 세분화된다. $h^{(\text{shared})}$는 공유 가중치를 뜻하며, 3개의 모델에서 동일하게 사용된다. $h^{(\text{1})}$~ $h^{(\text{3})}$ 은 각 모델의 독자적인 가중치를 뜻하며, 독립적으로 학습된다.
가중치 공유에 대해서
가중치를 공유하는 이유는 두 개의 작업을 수행하는 데에 필요한 사전 지식에는 동일한 부분이 있을 것이라는 가설에서 나온다. 따라서 접점이 전혀 없는 Task들을 멀티태스크 러닝으로 풀고자 한다면 성능 개선이 되지 않을 수 있다. 하지만 올바르게 설정된 멀티태스크 러닝에서라면 일반화 성능의 개선을 기대할 수 있다.
더 많은 데이터가 거의 확실하게 모델 성능을 개선하는 것을 떠올리면, 같은 데이터로 더 많은 문제를 풀려고 할 때 성능이 개선되는 이유를 짐작해볼 수 있다. 공유 가중치로 인해 성능이 개선되는 방향으로 가중치에 제약이 걸리기 때문이다.
💡 전이학습(Transfer Learning)과의 관계멀티태스크 러닝은 파라미터를 공유하는 것으로 성능을 끌어올린다는 면에서 전이학습과 유사하다. 전이학습에서는 이미 잘 작동하는 source task의 파라미터를 가져와서 target task의 성능을 개선한다. 멀티태스크 러닝에서는 source task와 target task를 동시에 학습한다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!