All About Decision Trees - 의사결정나무의 모든 것
의사결정나무(Decision Tree)는 1984년에 Leo Brieman의 논문에서 첫 등장하였다. 오랜 역사를 자랑하는 알고리즘이지만 의사결정나무는 2022년 기준 오늘날에도 많은 문제해결을 위해 사용되고 있으며, Kaggle 등의 데이터분석 대회에서 최상위권을 휩쓰는 앙상블 기법을 기반으로 한 모델(e.g. Random Forest)들의 뼈대가 되는 알고리즘이기도 하다. 단순한 알고리즘의 강력한 화이트박스 모델, 의사결정나무를 오늘의 포스팅에서 정확히 이해해 보자.
의사결정나무란 무엇인가?
원본 논문에서 사용한 예제를 살펴보자. 다음의 도표는 2008년 미국 대통령 선거의 결과의 요약으로, 특정 주(state)에서 버락 오바마와 힐러리 클린턴 중 누가 승리했는지 분석한 것이다.
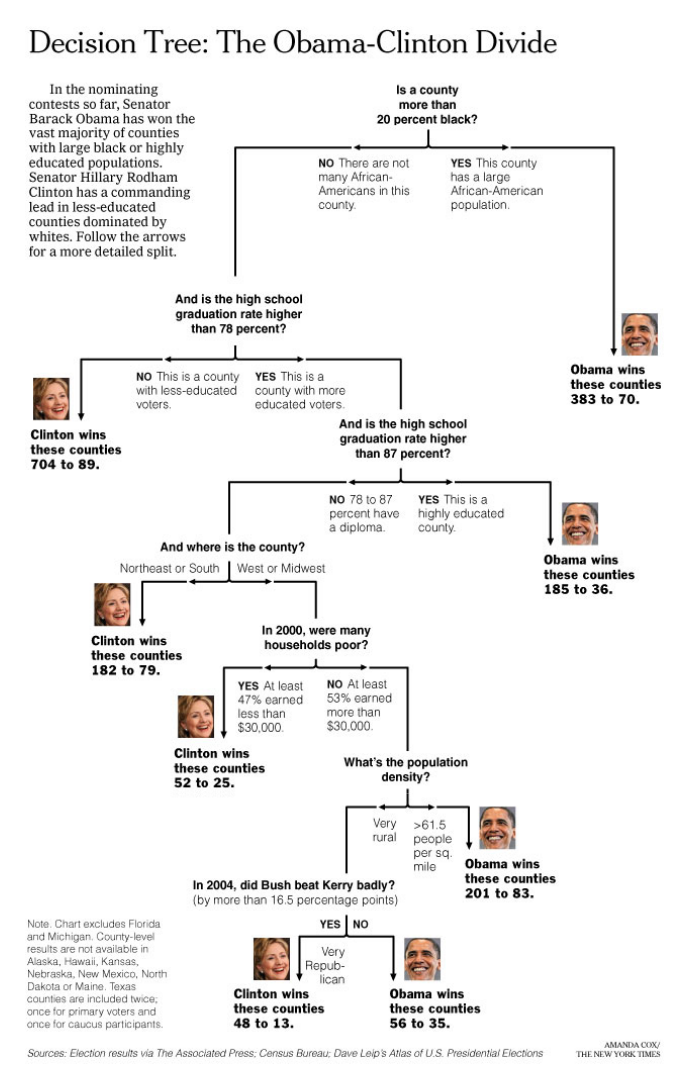
이것이 바로 의사결정나무이다. 모델을 잘 살펴보면 각 분기점마다 모든 예/아니오로 대답할 수 있는 어떤 조건을 통해 기존의 집합이 두 개의 부분집합으로 나뉘는 것을 알 수 있다. 이처럼 의사결정나무는 마치 사람이 스무고개를 하는 것과도 같은 과정을 통해서, 기존에 주어진 데이터 포인트를 여러 개의 노드(Node)로 분배한다.
Decision Tree 학습시키기
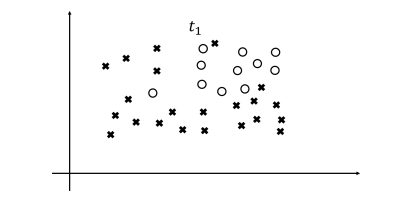
위 그림처럼 o와 x의 클래스들로 구성된 데이터가 있다고 하자. 또, 각각의 데이터 포인트는 2개의 연속값 특성(Continuous Feature)을 보유하며, 해당 값들은 위 그림의 $x$축과 $y$축에 해당한다고 생각해 보자. 새로운 데이터 포인트를 입력받았을 때, 그것이 o에 속하는지 x에 속하는지 분류할 수 있도록 의사결정나무를 학습시키는 과정을 살펴보겠다.
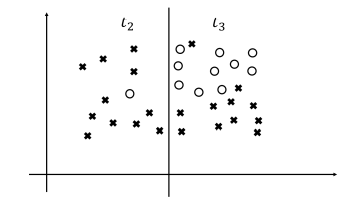
우선 주어진 데이터 포인트를 가장 잘 분할하도록, $x$축 혹은 $y$축에 평행한 선을 긋는다. 이것은 위의 미국 대통령 선거 도표에서 분기점을 만드는 것과 같은 행위이다. 가령 선 오른쪽의 점들은 “$x$축의 값이 $k$이상인가?” 라는 질문에 대해 “그렇다”라고 응답하는 점들인 것이다. 이제 생성된 부분집합에 대해 같은 분할을 원하는 만큼 반복한다.
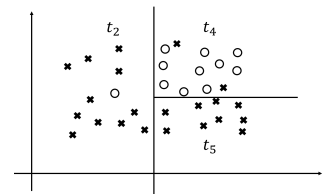
원하는 만큼 데이터셋의 분할이 이루어졌다면 중단한다. 이렇게 데이터셋을 분할하는 과정이 바로 의사결정나무에서 학습이 이루어지는 방식이다. 물론 이것은 매우 단순화된 예시이며, 수식을 포함한 자세한 학습 과정에 대해서는 후술하도록 한다. 우선 이렇게 학습된 의사결정나무를 가지고 어떻게 예측을 시행할 수 있는지 짧게 알아보자.
학습 알고리즘 상세
의사결정나무의 예측 방식에는 여러 가지 변형이 존재하지만 다음의 두 가지가 대표적이다.
분류 문제일 경우 :
- 새로운 데이터 포인트가 소속된 부분집합의 최빈값으로 예측한다.
- 만약 새로운 데이터 포인트가 들어왔는데 $t_4$ 영역에 속한다면, o로 분류될 것이다.
- 새로운 데이터 포인트가 들어왔는데 $t_5$ 영역에 속한다면, x로 분류될 것이다.
- 빈도수가 동률일 경우 Tiebreaking의 규칙은 임의로 정한다.
회귀 문제일 경우 : 새로운 데이터 포인트가 소속된 부분집합의 평균값으로 예측한다.
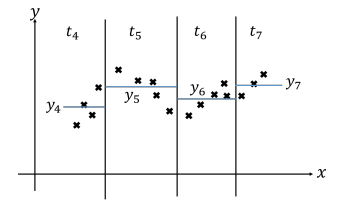
- 새로운 데이터 포인트가 소속된 부분집합의 평균값으로 예측한다.
- 만약 새로운 데이터 포인트가 들어왔는데 $t_5$ 영역에 속한다면, 예측값은 $y_5$가 될 것이다.
- 만약 새로운 데이터 포인트가 들어왔는데 $t_7$ 영역에 속한다면, 예측값은 $y_7$이 될 것이다.
- 혹은, 분할된 영역마다 선형회귀 모델을 따로 학습시키는 방법도 있다.
Decision Tree 학습시키기
그렇다면 의사결정나무는 어떻게 최적의 분할을 진행할까? 의사결정나무는 학습이 진행될 때마다 어떤 특성(Feature)을 사용해서, 어떤 값을 기준으로 분할을 진행해야 가장 좋은 분할을 이루어낼 수 있을지 알아내기 위해 Greedy Search를 진행한다. 이 말은 곧 가능한 모든 분할을 진행해본 뒤 가장 좋은 분할을 선택한다는 것이다.

“그런데 좋은 분할이란 도대체 무엇일까?”
의사결정나무는 기계학습 알고리즘인 만큼, 분할이 잘 이루어졌는지 기계가 이해할 수 있는 기준이 필요하다. 이를 위해서 분할이 이루어진 의사결정나무의 각 노드의 상태를 평가하는 수치적 기준이 필요하다.
- 회귀 문제를 의사결정나무로 풀 때는 평균제곱오차(Mean Squared Error)를 이용해 특정 노드의 상태를 평가할 수 있다.
분류 문제를 의사결정나무로 풀 때는 불순도 함수(Impurity Function)라는 것을 이용한다. 엔트로피(Entropy)와 지니계수(Gini Coefficient)가 대표적인 불순도 함수의 예시이다. $P=(p_1, \dots , p_k)$가 확률분포일 때, 즉 $\sum_i p_i=1$이고 $0\leq p_i$일 때, 엔트로피와 지니계수는 다음과 같이 정의된다.
\[\begin{align*} \text{Entropy}(P) &= -\sum_ip_i\log p_i\\ \text{Gini}(P) &= \frac{1}{2}\sum_i p_i (1-p_i) = \sum_{i<j}p_ip_j \end{align*}\]
💡 엔트로피 함수에서는 예외적으로 $0\log 0=0$으로 정의한다.
특정 노드의 엔트로피
의사결정나무가 잘 분할되었는지 평가하기 위해서는 먼저 각 노드의 불순도를 평가해야 한다. 예를 들어 아래 그림에서 $t_2$ 영역과 $t_3$ 영역의 엔트로피 불순도를 생각해 보자.
- $t_2$영역은 o가 1개, x가 11개 존재한다. 따라서 $p={\frac{1}{12}, \frac{11}{12}}$라는 확률분포를 생각해볼 수 있으며, 엔트로피는 수식에 따라 약 $0.2868$이 된다.
- $t_3$영역은 o가 10개, x가 11개 존재한다. 따라서 $p={\frac{10}{21}, \frac{11}{21}}$라는 확률분포를 생각해볼 수 있으며, 엔트로피는 수식에 따라 약 $0.6920$이 된다.
의사결정나무 전체의 불순도
이제 모든 단말 노드(leaf node)의 가중합으로 의사결정나무 전체의 불순도를 계산할 수 있다. 여기에서 가중치는 전체 데이터에서 해당 노드가 보유하고 있는 데이터 포인트의 비율이다. 각 노드의 불순도가 중요하지만 해당 노드가 전체 모델에 기여하는 비중이 다르다는 것이 직관이다. 따라서 위 도표의 경우 전체 의사결정나무의 엔트로피는 다음과 같다.
\[\frac{12}{33}\times0.2868 +\frac{21}{33}\times0.6920 \approx 0.5446\]분할 기준
이렇게 의사결정나무의 주어진 상태를 수치화해 평가할 수 있게 되었다. 이제 앞서 언급한 것처럼 Greedy Search를 통해 불순도를 최소화하는 분할을 찾아나가면 된다. 가능한 모든 분할을 진행해본 뒤 각 상태에서 불순도를 평가하고, 가장 작은 불순도를 제공하는 분할을 선택하는 것이다.
💡 만약 불순도를 개선시키는 분할이 더 이상 존재하지 않는다면 알고리즘이 종료된다.
알고리즘의 종료와 가지치기
기본적으로 의사결정나무는 더 이상 노드의 분할을 진행할 수 없을 때 성장을 중지한다. (이 때의 의사결정나무를 Full Tree라고 부른다.) 하지만 이것은 엄밀히 말하면 과적합(Overfitting)에 해당한다. 학습 데이터셋에 대해서 의사결정나무를 완벽하게 학습시키는 것이기 때문이다. 따라서 의사결정나무의 성장을 조금 일찍 종료시켜 새로운 데이터(Held-out data)에 대한 일반화 성능을 확보하는 전략이 널리 사용된다. 이것을 가지치기(Pruning)라고 한다. 대표적인 가지치기 전략의 예시를 소개한다.
- 사전 가지치기(Pre-Pruning) : 나무가 성장하기 전에 미리 억제하는 전략이다.
- 깊이(Depth) 기반 : $k$ 이상의 깊이에서는 자식 노드를 생성할 수 없도록 한다.
- 최소 원소 수 기반 : 원소가 $i$개 이하인 노드는 분할하지 않는다.
- 불순도 기반 : 불순도를 $\delta$ 이하로 개선시키는 분할은 시행하지 않는다.
- 깊이 페널티 : 불순도를 계산할 때 층수 $k$를 불순도에 더한 값을 사용한다. 즉, 불순도 개선과 깊이의 trade-off를 고려하는 것이다. 이 경우 특정 분할로 불순도가 줄어든다 하더라도 나무의 깊이를 증가시킨다면 분할이 기각될 수 있다.
- 사후 가지치기(Post-Pruning) : 성장을 끝낸 나무의 노드를 삭제하면서 줄여나가는 방식이다.
- Reduced Error Pruning : 같은 분할에 속하는 두 개의 단말 노드에 대해, 그 분할이 이루어졌을 때와 이루어지지 않았을 때의 검증 오차(Validation Error)를 비교한다. 분할하지 않는 쪽이 더 낮은 검증 오차를 보인다면 그 분할을 폐기하고, 두 단말 노드를 병합한다. 더 이상 검증 오차가 줄어들지 않을 때까지, 해당 과정을 반복적으로 시행한다.
포스트가 마음에 드셨다면, 좋아요를 남겨주세요!